Это короткий фрагмент для ознакомления с книгой.
 Скачать или читать эту книгу на КулЛиб
Скачать или читать эту книгу на КулЛиб Герберт Шилдт: С++ базовый курс

В этой книге описаны все основные средства языка С++ - от элементарных понятий до супервозможностей. После рассмотрения основ программирования на C++ (переменных, операторов, инструкций управления, функций, классов и объектов) читатель освоит такие более сложные средства языка, как механизм обработки исключительных ситуаций (исключений), шаблоны, пространства имен, динамическая идентификация типов, стандартная библиотека шаблонов (STL), а также познакомится с расширенным набором ключевых слов, используемых в .NET-программировании. Автор справочника - общепризнанный авторитет в области программирования на языках C и C++, Java и C# - включил в текст своей книги и советы программистам, которые позволят повысить эффективность их работы.
Книга рассчитана на широкий круг читателей, желающих изучить язык программирования С++.
Примеры программ работают со всеми компиляторами C++, включая Visual C++
Оглавление
Глава 1. Из истории создания C++ Глава 2. Обзор элементов языка C++ Глава 3. Основные типы данных Глава 4. Инструкции управления Глава 5. Массивы и строки Глава б. Указатели Глава 7. Функции, часть первая: основы Глава 8. Функции, часть вторая: ссылки, перегрузка и использование аргументов по умолчанию Глава 9. Еще о типах данных и операторах Глава 10. Структуры и объединения Глава 11. Введение в классы Глава 12. О классах подробнее Глава 13. Перегрузка операторов Глава 14. Наследование Глава 15. Виртуальные функции и полиморфизм Глава 16. Шаблоны Глава 17. Обработка исключительных ситуаций Глава 18. С++ - система ввода-вывода Глава 19. Динамическая идентификация типов и операторы приведения типа Глава 20. Пространства имен и другие темы Глава 21. Введение в стандартную библиотеку шаблонов Глава 22. Препроцессор C++ Приложение А. С-ориентнрованная система ввода-вывода Приложение Б. Использование устаревшего С++-компилятора Приложение В. .NET-расширения для C++ Предметный указательОб авторе
Герберт Шилдт (Herbert Schildt) — признанный авторитет в области программирования на языках С, C++ Java и С#, профессиональный Windows-программист, член комитетов ANSI/ISO, принимавших стандарт для языков С и C++. Продано свыше 3 миллионов экземпляров его книг. Они переведены на все самые распространенные языки мира. Шилдт — автор таких бестселлеров, как Полный справочник по С, Полный справочник по C++, Полный справочник по С#, Полный справочник по Java 2, и многих других книг, включая: Руководство для начинающих по C++, С#: A Beginner’s Guide и Java 2: A Beginner’s Guide. Шилдт— обладатель степени магистра в области вычислительной техники (университет шт. Иллинойс). Его контактный телефон (в консультационном отделе): (217) 586-4683.Введение
Цель этой книги — научить писать программы на C++ — самом мощном языке программирования наших дней. Для освоения представленного здесь материала никакого предыдущего опыта в области программирования не требуется. Мы начнем с азов, знание которых позволит читателю осилить сначала фундаментальные понятия языка, а затем и его ядро. Изучив базовый курс, вы справитесь и с более сложными темами, освоение которых даст вам право считать себя вполне сложившимся программистом на C++. Язык C++ — это ключ к современному объектно-ориентированному программированию. Он создан для разработки высокопроизводительного программного обеспечения и чрезвычайно популярен среди программистов. Сегодня быть профессиональным программистом высокого класса означает быть компетентным в C++. Этот язык не просто популярен. Он обеспечивает концептуальный фундамент, на который опираются другие языки программирования и многие современные средства обработки данных. Не случайно ведь потомками C++ стали такие почитаемые языки, как C# и Java. Поскольку язык C++ предназначен для профессионального программирования, для изучения он не самый простой; тем не менее, C++ — самый лучший язык для изучения. Освоив C++, вы сможете писать профессиональные высокопроизводительные программы. Кроме того, вы сможете легко изучить такие языки программирования, как C# и Java, поскольку они используют тот же базовый синтаксис и те же принципы разработки.Что нового в третьем издании
За время, прошедшее с момента выхода предыдущего издания этой книги, язык C++ не претерпел никаких изменений. Однако изменилась вычислительная среда. Например, доминирующее положение в Web-программировании занял язык Java, появилась система .NET Framework и язык С#. Но мощь C++ за прошедшие несколько лет ничуть не убавилась. C++ был, есть и еще долго будет основным языком "классных" программистов. Общая структура и организация третьего издания практически повторяют второе. Большинство изменений связано с обновлением текста или его дополнением. В одних случаях лучше раскрыта тема, а в других добавлено описание современной среды программирования. Книга расширена также за счет нескольких новых разделов. Кроме того, добавлено два приложения. В одном описаны определенные компанией Microsoft ключевые слова, которые используются для создания управляемого кода, предназначенного для среды .NET Framework. В другом разъясняется, как адаптировать код, приведенный в этой книге, к более старым и нестандартным компиляторам. Наконец, все примеры программ были протестированы с использованием таких компиляторов, как Visual Studio .Net (Microsoft) и C++ Builder (Borland).О версии C++
Материал этой книги описывает Standard C++. Эта версия C++ определена Американским национальным институтом стандартов (American National Standards Institute — ANSI) и Международной организацией по стандартизации (International Standards Organization — ISO) в качестве стандарта для C++, который поддерживается практически всеми известными компиляторами. Поэтому, используя эту книгу, вы можете быть уверены в том, что освоенное вами сегодня непременно будет применено завтра.Как работать с этой книгой
Изучайте любой язык программирования (в том числе и C++), программируя. Это — лучший способ. Поэтому, прочитав очередной раздел, закрепите материал на практике. Прежде чем переходить к следующему разделу, убедитесь в том, что вы понимаете, почему примеры программ делают то, что они делают. Полезно также экспериментировать с программами, изменяя одну или две строки и анализируя влияние этих изменений на результаты. Чем больше вы будете программировать, тем выше будет ваш уровень как программиста.Если вы работаете под управлением Windows
Если на вашем компьютере установлена система Windows, и ваша цель — создание Windows-ориентированных программ, вы сделали правильный выбор, решив изучать C++, поскольку C++ — это родной язык для Windows. Однако ни в одном из примеров этой книги не используется Windows-интерфейс GUI (graphical user interface — графический интерфейс пользователя). Все приведенные здесь примеры являются консольными, т.е. приложениями, запускаемыми из командной строки (поскольку не имеют графического интерфейса). Дело в том, что GUI-программы отличаются высокой сложностью и большим размером. Кроме того, они используют множество методов, которые напрямую не связаны с языком C++. Поэтому они не совсем подходят для обучения языку программирования. Однако это не мешает использовать Windows-ориентированный компилятор для компиляции программ из этой книги, поскольку он автоматически создаст консольный сеанс, позволяющий выполнить программу. Освоив C++, вы сможете применить свои знания к Windows-программированию. Windows-программирование на основе C++ позволяет использовать библиотеки классов, например MFC или .NET Framework, которые значительно упрощают разработку Windows-программ.Программный код — из Web-пространства
Помните, что исходный код всех программ, приведенных в этой книге, можно загрузить с Web-сайта с адресом: http://www.osborne.com. Загрузка кода избавит вас от необходимости вводить текст программ вручную.Что еще почитать
Книга C++: базовый курс — это ваш "ключ" к серии книг по программированию, написанных Гербертом Шилдтом. Ниже перечислены те из них, которые могут представлять для вас интерес. Те, кто желает подробнее изучить язык C++, могут обратиться к следующим книгам. ■ Полный справочник по C++ ■ Руководство для начинающих по C++ ■ Освой самостоятельно C++ за 21 день ■ STL Programming from the Ground Up ■ Справочник программиста пo C/C++ Тем, кого интересует программирование на языке Java, мы рекомендуем такие издания. ■ Java 2: A Beginner’s Guide ■ Полный справочник по Java 2 ■ Java 2: Programmer’s Reference Если вы желаете научиться программировать на С#, обратитесь к следующим книгам. ■ С#: A Beginner’s Guide ■ Полный справочник по C# Тем, кто интересуется Windows-программированием, мы можем предложить такие книги Шилдта. ■ Windows 98 Programming from the Ground Up ■ Windows 2000 Programming from the Ground Up ■ MFC Programming from the Ground Up ■ The Windows Annotated Archives Если вы хотите поближе познакомиться с языком С, который является фундаментом всех современных языков программирования, обратитесь к следующим книгам. ■ Полный справочник по С ■ Освой самостоятельно С за 21 деньЕсли вам нужны четкие ответы, обращайтесь к Герберту Шилдту, общепризнанному авторитету в области программирования.
Ждем ваших отзывов!
Вы, уважаемый читатель, и есть главный критик и комментатор этой книги. Мы ценим ваше мнение и хотим знать, что было сделано нами правильно, что можно было сделать лучше и что еще вы хотели бы увидеть изданным нами. Нам интересно услышать и любые другие замечания, которые вам хотелось бы высказать в наш адрес. Мы ждем ваших комментариев и надеемся на них. Вы можете прислать нам бумажное или электронное письмо либо просто посетить наш Web-cepвep и оставить свои замечания там. Одним словом, любым, удобным для вас способом дайте нам знать, нравится или нет вам эта книга, а также выскажите свое мнение о том, как сделать наши книги более интересными для вас. Посылая письмо или сообщение, не забудьте указать название книги и ее авторов, а также ваш обратный адрес. Мы внимательно ознакомимся с вашим мнением и обязательно учтем его при отборе и подготовке к изданию последующих книг. Наши координаты: E-mail: info@williamspublishing.com WWW: http: //www.williamspublishing. com Адреса для писем: из России: 115419, Москва, а/я 783 из Украины: 03150, Киев, а/я 152от редактора FB2
Так как эта электронная книга будет отображаться на устройствах с разными размерами экрана, то располежение текста книги будет разным. Так же в книге используется форматирование кода (сдвиг вправо пробелами), а в некоторых читалках пять пробелов отображается как один (AlReader2). Поэтому я сделал пробел(сдвиг) в виде юникода если ваше устройство и/или читалка поддерживают юникод, то у вас будет отображаться пробел в коде, если неподдерживают то будет отображаться квадрат (вместо него в программе компиляторе пишите пару пробелов, или один TAB) Пример: <<<тут должно быть 3 квадрата... если их нет то код будет сдвинут вправо в нужных местах (ваше устройство поддерживает юникод). Если вы их видите то в местах сдвига (там где они отображаются) пишите пару пробелов (или игнорируйте их) Так же обращайте внимание на построчный коментрарий: // на маленьком экране он может разбиться на 2 строки!код программы //коментарий
коментарий может разбиться на две строки
1-я строка-ком
2-я строка-ентарий
в этом случае компилятор будет ругаться на команду ентарий в компиляторе он будет отображаться другим цветом нежели
//ком
в итоге программа небудет запускаться. Лечится это перемещением ентарий на строку //ком
-> 1-я строка //коментарий
Настройка отображения кода: (для того чтобы было удобее читать код программ) AlReader2: меню=> настройки=> стили текста=> код=> настройте: выравнивание=К левому краю, цвет=(выберите цвет), отступ слева=нет отступа, отступ справа=нет отступа, отступ начала абзаца= (убрать галочку), остальные настройки на ваш выбор. В других программах настройки аналогичны...
Так как каждый компилятор и среда разработки "по свойму нарушает стандарт C++" (что-то убирает или добавляет), а так же из за развития C++ с момента его создания, некоторые программы этой книги нужно писать по другому. По этой причине я привожу список сайтов на которых вы сможете найти ответы на интересующие вас вопросы: http://codenet.ru/ http://hashcode.ru http://rsdn.ru/ http://ci-plus-plus.blogspot.com/ http://programmersclub.ru/ http://cyberforum.ru/
Глава 1: Из истории создания C++
Язык C++ — единственный (из самых значительных) язык программирования, который может освоить любой программист. Это может показаться очень серьезным заявлением, но оно — не преувеличение. C++ — это центр притяжения, вокруг которого "вращается" всё современное программирование. Его синтаксис и принципы разработки определяют суть объектно-ориентированного программирования. Более того, C++ проложил "лыжню" для разработки языков будущего. Например, как Java, так и C# — прямые потомки языка C++. C++ также можно назвать универсальным языком программирования, поскольку он позволяет программистам обмениваться идеями. Сегодня быть профессиональным программистом высокого класса означает быть компетентным в C++. C++ — это ключ к современному программированию. Приступая к изучению C++, важно знать, как он вписывается в исторический контекст языков программирования. Понимая, что привело к его созданию, какие принципы разработки он представляет и что он унаследовал от своих предшественников, вам будет легче оценить суть новаторства и уникальность средств C++. Именно поэтому в данной главе вам предлагается сделать краткий экскурс в историю создания языка программирования C++, заглянуть в его истоки, проанализировать его взаимоотношения с непосредственным предшественником (С), рассмотреть его возможности (области применения) и принципы программирования, которые он поддерживает. Здесь также вы узнаете, какое место занимает C++ среди других языков программирования.Истоки C++
История создания C++ начинается с языка С. И немудрено: C++ построен на фундаменте С. C++ и в самом деле представляет собой супермножество языка С. (Все компиляторы C++ можно использовать для компиляции С-программ.) C++ можно назвать расширенной и улучшенной версией языка С, в которой реализованы принципы объектно-ориентированного программирования. C++ также включает ряд других усовершенствований языка С, например расширенный набор библиотечных функций. При этом "вкус и запах" C++ унаследовал непосредственно из языка С. Чтобы до конца понять и оценить достоинства C++, необходимо понять все "как" и "почему" в отношении языка С.Создание языка С
Появление языка С потрясло компьютерный мир. Его влияние нельзя было переоценить, поскольку он коренным образом изменил подход к программированию и его восприятие. Язык С стал считаться первым современным "языком программиста", поскольку до его изобретения компьютерные языки в основном разрабатывались либо как учебные упражнения, либо как результат деятельности бюрократических структур. С языком С все обстояло иначе. Он был задуман и разработан реальными, практикующими программистами и отражал их подход к программированию. Его средства были многократно обдуманы, отточены и протестированы людьми, которые действительно работали с этим языком. В результате этого процесса появился язык, который понравился многим программистам-практикам. Язык С быстро завоевал умы и сердца многочисленных приверженцев, у которых возникло к новому языку почти религиозное чувство, что способствовало быстрому и широкому его распространению в сообществе программистов. Короче говоря, С — это язык, который разработан программистами для программистов. Именно это и обусловило его бешеный успех. Язык С изобрел Дэнис Ритчи (Dennis Ritchie) для компьютера PDP-11 (разработка компании DEC — Digital Equipment Corporation), который работал под управлением операционной системы (ОС) UNIX. Язык С — это результат процесса разработки, который сначала был связан с другим языком — BCPL, созданным Мартином Ричардсом (Martin Richards). Язык BCPL индуцировал появление языка, получившего название В (его автор — Кен Томпсон (Ken Thompson)), который в свою очередь привел к разработке языка С. Это случилось в начале 70-х годов. На протяжении многих лет стандартом для языка С де-факто служил язык, поддерживаемый ОС UNIX и описанный в книге Брайана Кернигана (Brian Kernighan) и Дэниса Ритчи The С Programming Language (Prentice-Hall, 1978). Однако формальное отсутствие стандарта стало причиной расхождений между различными реализациями языка С. Чтобы изменить ситуацию, в начале лета 1983 г. был учрежден комитет по созданию ANSI-стандарта, призванного — раз и навсегда — определить язык С. Конечная версия этого стандарта была принята в декабре 1989, а его первая копия стала доступной для желающих в начале 1900. Эта версия языка С получила название С89, и именно она явилась фундаментом, на котором был построен язык C++. На заметку: Стандарт С был обновлен в 1999 году, и эта версия языка С получила название С99. Новый стандарт содержит ряд новых средств, причем некоторые из них позаимствованы из C++, тем не менее они полностью совместимы с оригинальным стандартом С89. Насколько мне известно, на данный момент ни один из широко доступных компиляторов не поддерживает версию С99, и по-прежнему версия С89 определяет то, что обычно подразумевается под языком С. Более того, именно стандарт С89 послужил основой для создания языка C++. Вполне возможно, что будущий стандарт языка C++ будет включать средства, добавленные версией С99, но пока они не являются частью C++.Язык С часто называют компьютерным языком "среднего уровня". Применительно к С это определение не имеет негативного оттенка, поскольку оно отнюдь не означает, что язык С менее мощный и развитый (по сравнению с языками "высокого уровня") или его сложно использовать (подобно ассемблеру). (Для языка ассемблера характерно символическое представление реального машинного кода, который может выполнять компьютер.) С называют языком среднего уровня, поскольку он сочетает элементы языков высокого уровня (например Pascal, Modula-2 или Visual Basic) с функциональностью ассемблера. С точки зрения теории в язык высокого уровня заложено стремление дать программисту все, что он может захотеть, в виде встроенных средств. Язык низкого уровня не обеспечивает программиста ничем, кроме доступа к реальным машинным командам. Язык среднего уровня предоставляет программистам некоторый (небольшой) набор инструментов, позволяя им самим разрабатывать конструкции более высокого уровня. Другими словами, язык среднего уровня предлагает программисту встроенную мощь в сочетании с гибкостью. Будучи языком среднего уровня, С позволяет манипулировать битами, байтами и адресами, т.е. базовыми элементами, с которыми работает компьютер. Таким образом, в С не предусмотрена попытка отделить аппаратные средства компьютера от программных. Например, размер целочисленного значения в С напрямую связан с размером слова центрального процессора (ЦП). В большинстве языков высокого уровня существуют встроенные инструкции, предназначенные для чтения и записи дисковых файлов. В языке С все эти процедуры выполняются посредством вызова библиотечных функций, а не с помощью ключевых слов, определенных в самом языке. Такой подход повышает гибкость языка С. Язык С позволяет программисту (правильнее сказать, стимулирует его) определять подпрограммы для выполнения операций высокого уровня. Эти подпрограммы называются функциями. Функции имеют очень большое значение для языка С. Их можно назвать строительными блоками С. Программист может без особых усилий создать библиотеку функций, предназначенную для выполнения различных задач, которые используются его программой. В этом смысле программист может персонализировать С в соответствии со своими потребностями. Необходимо упомянуть еще об одном аспекте языка С, который очень важен для C++: С — структурированный язык. Самой характерной особенностью структурированного языка является использование блоков. Блок — это набор инструкций, которые логически связаны между собой. Например, представьте себе инструкцию IF, которая при успешной проверке своего выражения должна выполнить пять отдельных инструкций. А если эти инструкции (специальным образом) сгруппировать и обращаться к ним как к единому целому, то такая группа образует блок. Структурированный язык поддерживает концепцию подпрограмм и локальных переменных. Локальная переменная — это обычная переменная, которая известна только подпрограмме, в которой она определена. Структурированный язык также поддерживает ряд таких циклических конструкций, как while, do-while и for. Однако использование инструкции goto либо запрещается, либо не рекомендуется, и не несет в себе той смысловой нагрузки для передачи управления, какая присуща ей в таких языках программирования, как BASIC или FORTRAN. Структурированный язык позволяет структурировать текст программы, т.е. делать отступы при написании инструкций, и не требует строгой привязки к полям, как это реализовано в ранних версиях языка FORTRAN. Наконец (и это, возможно, самое важное), язык С не несет ответственности за действия программиста. Основной принцип С состоит в том, чтобы позволить программисту делать все, что он хочет, но за последствия, т.е. за все, что делает программа (пусть даже очень необычное, что-то из ряда вон или даже подозрительное), отвечает не язык, а программист. Язык С предоставляет программисту практически полную власть над компьютером, но эта власть ложится на его плечи тяжким бременем ответственности.
Предпосылки возникновения языка C++
Приведенная выше характеристика языка С может вызвать справедливое недоумение: зачем же тогда, мол, был изобретен язык C++? Если С — такой хороший и полезный язык, то почему возникла необходимость в чем-то еще? Оказывается, все дело в сложности. На протяжении всей истории программирования усложнение программ заставляло программистов искать пути, которые бы позволили справиться со сложностью. C++ можно считать одним из способов ее преодоления. Попробуем лучше раскрыть эту взаимосвязь. Отношение к программированию резко изменилось с момента изобретения компьютера. Основная причина — стремление "укротить" всевозрастающую сложность программ. Например, программирование для первых вычислительных машин заключалось в переключении тумблеров на их передней панели таким образом, чтобы их положение соответствовало двоичным кодам машинных команд. Пока длины программ не превышали нескольких сотен команд, такой метод еще имел право на существование. Но по мере их дальнейшего роста был изобретен язык ассемблер, чтобы программисты могли использовать символическое представление машинных команд. Поскольку программы продолжали расти в размерах, желание справиться с более высоким уровнем сложности вызвало появление языков высокого уровня, разработка которых дала программистам больше инструментов (новых и разных). Первым широко распространенным языком программирования был, конечно же, FORTRAN. Несмотря на то что это был очень значительный шаг на пути прогресса в области программирования, FORTRAN все же трудно назвать языком, который способствовал написанию ясных и простых для понимания программ. Шестидесятые годы двадцатого столетия считаются периодом появления структурированного программирования. Именно такой метод программирования и был реализован в языке С. С помощью структурированных языков программирования можно было писать программы средней сложности, причем без особых героических усилий со стороны программиста. Но если программный проект достигал определенного размера, то даже с использованием упомянутых структурированных методов его сложность резко возрастала и оказывалась непреодолимой для возможностей программиста. Когда (к концу 70-х) к "критической" точке подошло довольно много проектов, стали рождаться новые технологии программирования. Одна из них получила название объектно-ориентированного программирования (ООП). Вооружившись методами ООП, программист мог справляться с программами гораздо большего размера, чем прежде. Но язык С не поддерживал методов ООП. Стремление получить объектно-ориентированную версию языка С в конце концов и привело к созданию C++. Несмотря на то что язык С был одним из самых любимых и распространенных профессиональных языков программирования, настало время, когда его возможности по написанию сложных программ достигли своего предела. Желание преодолеть этот барьер и помочь программисту легко справляться с еще более сложными программами — вот что стало основной причиной создания C++.Рождение C++
Итак, C++ появился как ответ на необходимость преодолеть еще большую сложность программ. Он был создан Бьерном Страуструпом (Bjarne Stroustrup) в 1979 году в компании Bell Laboratories (г. Муррей-Хилл, шт. Нью-Джерси). Сначала новый язык получил имя "С с классами" (С with Classes), но в 1983 году он стал называться C++. C++ полностью включает язык С. Как упоминалось выше, С — это фундамент, на котором был построен C++. Язык C++ содержит все средства и атрибуты С и обладает всеми его достоинствами. Для него также остается в силе принцип С, согласно которому программист, а не язык, несет ответственность за результаты работы своей программы. Именно этот момент позволяет понять, что изобретение C++ не было попыткой создать новый язык программирования. Это было скорее усовершенствование уже существующего (и при этом весьма успешного) языка. Большинство новшеств, которыми Страуструп обогатил язык С, было предназначено для поддержки объектно-ориентированного программирования. По сути, C++ стал объектно-ориентированной версией языка С. Взяв язык С за основу, Страуструп подготовил плавный переход к ООП. Теперь, вместо того, чтобы изучать совершенно новый язык, С-программисту достаточно было освоить только ряд новых средств, и он мог пожинать плоды использования объектно-ориентированной технологии программирования. Однако в основу C++ лег не только язык С. Страуструп утверждает, что некоторые объектно-ориентированные средства были инспирированы другим объектно-ориентированным языком, а именно Simula67. Таким образом, C++ представляет собой симбиоз двух мощных методологий программирования. Создавая C++, Страуструп понимал, насколько важно, сохранить изначальную суть языка С, т.е. его эффективность, гибкость и принципы разработки, внести в него поддержку объектно-ориентированного программирования. К счастью, эта цель была достигнута. C++ по-прежнему предоставляет программисту свободу действий и власть над компьютером (которые были присущи языку С), расширяя при этом его (программиста) возможности за счет использования объектов. Несмотря на то что C++ изначально был нацелен на поддержку очень больших программ, этим, конечно же, его использование не ограничивалось. И в самом деле, объектно-ориентированные средства C++ можно эффективно применять практически к любой задаче программирования. Неудивительно, что C++ используется для создания компиляторов, редакторов, компьютерных игр и программ сетевого обслуживания. Поскольку C++ обладает эффективностью языка С, то программное обеспечение многих высокоэффективных систем построено с использованием C++. Кроме того, C++ — это язык, который чаще всего выбирается для Windows-программирования. Важно также помнить следующее. Поскольку C++ является супермножеством языка С, то, научившись программировать на C++, вы сможете также программировать и на С! Таким образом, приложив усилия к изучению только одного языка программирования, вы в действительности изучите сразу два.Эволюция C++
С момента изобретения C++ претерпел три крупных переработки, причем каждый раз язык как дополнялся новыми средствами, так и в чем-то изменялся. Первой ревизии он был подвергнут в 1985 году, а второй — в 1990. Третья ревизия имела место в процессе стандартизации, который активизировался в начале 1990-х. Специально для этого был сформирован объединенный ANSI/ISO-комитет (я был его членом), который 25 января 1994 года принял первый проект предложенного на рассмотрение стандарта. В этот проект были включены все средства, впервые определенные Страуструпом, и добавлены новые. Но в целом он отражал состояние C++ на тот момент времени. Вскоре после завершения работы над первым проектом стандарта C++ произошло событие, которое заставило значительно расширить существующий стандарт. Речь идет о создании Александром Степановым стандартной библиотеки шаблонов (Standard Template Library — STL). Как вы узнаете позже, STL — это набор обобщенных функций, которые можно использовать для обработки данных. Он довольно большой по размеру. Комитет ANSI/ISO проголосовал за включение STL в спецификацию C++. Добавление STL расширило сферу рассмотрения средств C++ далеко за пределы исходного определения языка. Однако включение STL, помимо прочего, замедлило процесс стандартизации C++, причем довольно существенно. Помимо STL, в сам язык было добавлено несколько новых средств и внесено множество мелких изменений. Поэтому версия C++ после рассмотрения комитетом по стандартизации стала намного больше и сложнее по сравнению с исходным вариантом Страуструпа. Конечный результат работы комитета датируется 14 ноября 1997 года, а реально ANSI/ISO-стандарт языка C++ увидел свет в 1998 году. Именно эта спецификация C++ обычно называется Standard C++. И именно она описана в этой книге. Эта версия C++ поддерживается всеми основными С++-компиляторами, включая Visual C++ (Microsoft) и C++ Builder (Borland). Поэтому код программ, приведенных в этой книге, полностью применим ко всем современным С++-средам.Что такое объектно-ориентированное программирование
Поскольку именно принципы объектно-ориентированного программирования были основополагающими для разработки C++, важно точно определить, что они собой представляют. Объектно-ориентированное программирование объединило лучшие идеи структурированного с рядом мощных концепций, которые способствуют более эффективной организации программ. Объектно-ориентированный подход к программированию позволяет разложить задачу на составные части таким образом, что каждая составная часть будет представлять собой самостоятельный объект, который содержит собственные инструкции и данные. При таком подходе существенно понижается общий уровень сложности программ, что позволяет программисту справляться с более сложными программами, чем раньше (т.е. написанными при использовании структурированного программирования). Все языки объектно-ориентированного программирования характеризуются тремя общими признаками: инкапсуляцией, полиморфизмом и наследованием. Рассмотрим кратко каждый из них (подробно они будут описаны ниже в этой книге).Инкапсуляция
Ни для кого не секрет, что все программы, как правило, состоят из двух основных элементов: инструкций (кода) и данных. Код — это часть программы, которая выполняет действия, а данные представляют собой информацию, на которую направлены эти действия. Инкапсуляция — это такой механизм программирования, который связывает воедино код и данные, которые он обрабатывает, чтобы обезопасить их как от внешнего вмешательства, так и от неправильного использования. В объектно-ориентированном языке код и данные могут быть связаны способом, при котором создается самостоятельный черный ящик. В этом "ящике" содержатся все необходимые (для обеспечения самостоятельности) данные и код. При таком связывании кода и данных создается объект, т.е. объект — это конструкция, которая поддерживает инкапсуляцию. Внутри объекта, код, данные или обе эти составляющие могут быть закрытыми в "рамках" этого объекта или открытыми. Закрытый код (или данные) известен и доступен только другим частям того же объекта. Другими словами, к закрытому коду или данным не может получить доступ та часть программы, которая существует вне этого объекта. Открытый код (или данные) доступен любым другим частям программы, даже если они определены в других объектах. Обычно открытые части объекта используются для предоставления управляемого интерфейса с закрытыми элементами объекта.Полиморфизм
Полиморфизм (от греческого слова polymorphism, означающего "много форм") — это свойство, позволяющее использовать один интерфейс для целого класса действий. Конкретное действие определяется характерными признаками ситуации. В качестве простого примера полиморфизма можно привести руль автомобиля. Для руля (т.е. интерфейса) безразлично, какой тип рулевого механизма используется в автомобиле. Другим словами, руль работает одинаково, независимо от того, оснащен ли автомобиль рулевым управлением прямого действия (без усилителя), рулевым управлением с усилителем или механизмом реечной передачи. Если вы знаете, как обращаться с рулем, вы сможете вести автомобиль любого типа. Тот же принцип можно применить к программированию. Рассмотрим, например, стек, или список, добавление и удаление элементов к которому осуществляется по принципу "последним прибыл — первым обслужен". У вас может быть программа, в которой используются три различных типа стека. Один стек предназначен для целочисленных значений, второй — для значений с плавающей точкой и третий — для символов. Алгоритм реализации всех стеков — один и тот же, несмотря на то, что в них хранятся данные различных типов. В необъектно-ориентированном языке программисту пришлось бы создать три различных набора подпрограмм обслуживания стека, причем подпрограммы должны были бы иметь различные имена, а каждый набор — собственный интерфейс. Но благодаря полиморфизму в C++ можно создать один общий набор подпрограмм (один интерфейс), который подходит для всех трех конкретных ситуаций. Таким образом, зная, как использовать один стек, вы можете использовать все остальные. В более общем виде концепция полиморфизма выражается фразой "один интерфейс — много методов". Это означает, что для группы связанных действий можно использовать один обобщенный интерфейс. Полиморфизм позволяет понизить уровень сложности за счет возможности применения одного и того же интерфейса для задания целого класса действий. Выбор же конкретного действия (т.е. функции) применительно к той или иной ситуации ложится "на плечи" компилятора. Вам, как программисту, не нужно делать этот выбор вручную. Ваша задача — использовать общий интерфейс. Первые языки объектно-ориентированного программирования были реализованы в виде интерпретаторов, поэтому полиморфизм поддерживался во время выполнения программ. Однако C++ — это транслируемый язык (в отличие от интерпретируемого). Следовательно, в C++ полиморфизм поддерживается на уровне как компиляции программы, так и ее выполнения.Наследование
Наследование — это процесс, благодаря которому один объект может приобретать свойства другого. Благодаря наследованию поддерживается концепция иерархической классификации. В виде управляемой иерархической (нисходящей) классификации организуется большинство областей знаний. Например, яблоки Красный Делишес являются частью классификации яблоки, которая в свою очередь является частью класса фрукты, а тот — частью еще большего класса пища. Таким образом, класс пища обладает определенными качествами (съедобность, питательность и пр.), которые применимы и к подклассу фрукты. Помимо этих качеств, класс фрукты имеет специфические характеристики (сочность, сладость и пр.), которые отличают их от других пищевых продуктов. В классе яблоки определяются качества, специфичные для яблок (растут на деревьях, не тропические и пр.). Класс Красный Делишес наследует качества всех предыдущих классов и при этом определяет качества, которые являются уникальными для этого сорта яблок. Если не использовать иерархическое представление признаков, для каждого объекта пришлось бы в явной форме определить все присущие ему характеристики. Но благодаря наследованию объекту нужно доопределить только те качества, которые делают его уникальным внутри его класса, поскольку он (объект) наследует общие атрибуты своего родителя. Следовательно, именно механизм наследования позволяет одному объекту представлять конкретный экземпляр более общего класса.C++ и реализация ООП
В этой книге показано, что многие средства C++ предназначены для поддержки инкапсуляции, полиморфизма и наследования. Однако следует помнить, что язык C++ можно использовать для написания программ любого типа. Тот факт, что C++ поддерживает объектно-ориентированное программирование, не означает, что С++-программист может писать только объектно-ориентированные программы. Одним из самых важных достоинств языка C++ (как и его предшественника, языка С) является гибкость.Связь C++ с языками Java и C#
Вероятно, многие читатели знают о существовании таких языков программирования, как Java и С#. Язык Java разработан в компании Sun Microsystems, a C# — в компании Microsoft. Поскольку иногда возникает путаница относительно того, какое отношение эти два языка имеют к C++, попробуем внести ясность в этот вопрос. C++ является родительским языком для Java и С#. И хотя разработчики Java и C# добавили к первоисточнику, удалили из него или модифицировали различные средства, в целом синтаксис этих трех языков практически идентичен. Более того, объектная модель, используемая C++, подобна объектным моделям языков Java и С#. Наконец, очень сходно общее впечатление и ощущение от использования всех этих языков. Это значит, что, зная C++, вы можете легко изучить Java или С#. Схожесть синтаксисов и объектных моделей — одна из причин быстрого освоения (и одобрения) этих двух языков многими опытными С++-программистами. Обратная ситуация также имеет место: если вы знаете Java или С#, изучение C++ не доставит вам хлопот. Основное различие между C++, Java и C# заключается в типе вычислительной среды, для которой разрабатывался каждый из этих языков. C++ создавался с целью написания высокоэффективных программ, предназначенных для выполнения под управлением определенной операционной системы и в расчете на ЦП конкретного типа. Например, если вы хотите написать высокоэффективную программу для выполнения на процессоре Intel Pentium под управлением операционной системы Windows, лучше всего использовать для этого язык C++. Языки Java и C# разработаны в ответ на уникальные потребности сильно распределенной сетевой среды, которая может служить типичным примером современных вычислительных сред. Java позволяет создавать межплатформенный (совместимый с несколькими операционными средами) переносимый программный код для Internet. Используя Java, можно написать программу, которая будет выполняться в различных вычислительных средах, т.е. в широком диапазоне операционных систем и типов ЦП. Таким образом, Java-пpoгpaммa может свободно "бороздить просторами" Internet. C# разработан для среды .NET Framework (Microsoft), которая поддерживает многоязычное программирование (mixed-language programming) и компонентно-ориентированный код, выполняемый в сетевой среде. Несмотря на то что Java и C# позволяют создавать переносимый программный код, который работает в сильно распределенной среде, цена этой переносимости — эффективность. Java-пpoгpaммы выполняются медленнее, чем С++-программы. То же справедливо и для С#. Поэтому, если вы хотите создавать высокоэффективные приложения, используйте C++. Если же вам нужны переносимые программы, используйте Java или С#. И последнее. Языки C++, Java и C# предназначены для решения различных классов задач. Поэтому вопрос "Какой язык лучше?" поставлен некорректно. Уместнее задать вопрос по-другому: "Какой язык наиболее подходит для решения данной задачи?".Глава 2: Обзор элементов языка C++
Самым трудным в изучении языка программирования, безусловно, является то, что ни один его элемент не существует изолированно от других. Компоненты языка работают вместе, можно сказать, в дружном "коллективе". Такая тесная взаимосвязь усложняет рассмотрение одного аспекта C++ без рассмотрения других. Зачастую обсуждение одного средства предусматривает предварительное знакомство с другим. Для преодоления подобных трудностей в этой главе приводится краткое описание таких элементов C++, как общий формат С++-программы, основные инструкции управления и операторы. При этом мы не будем углубляться в детали, а сосредоточимся на общих концепциях создания С++-программы. Большинство затронутых здесь тем более подробно рассматриваются в остальных главах книги. Поскольку изучать язык программирования лучше всего путем реального программирования, мы рекомендуем читателю собственноручно выполнять приведенные в этой книге примеры на своем компьютере.Первая С++-программа
Прежде чем зарываться в теорию, рассмотрим простую С++-программу. Начнем с вывода текста, а затем перейдем к ее компиляции и выполнению.
/* Программа №1 - Первая С++-программа.
Введите эту программу, затем скомпилируйте ее и выполните.
*/
#include <iostream>
using namespace std;
// main() - начало выполнения программы.
int main()
{
cout << "Это моя первая С++-программа.";
return 0;
}
Итак, вы должны выполнить следующие действия.
1. Ввести текст программы.
2. Скомпилировать ее.
3. Выполнить.
Исходный код — это текстовая форма программы. Объектный код — это форма программы, которую может выполнить компьютер.
Прежде чем приступать к выполнению этих действии, необходимо определить два термина: исходный код и объектный код. Исходный код — это версия программы, которую может читать человек. Приведенный выше листинг — это пример исходного кода Выполняемая версия программы называется объектным, или выполняемым, кодом.
Ввод текста программы
Программы, представленные в этой книге, можно загрузить с Web-сайта компании Osborne с адресом: www.osborne.com. При желании вы можете ввести текст программ вручную. В этом случае необходимо использовать какой-нибудь текстовый редактор (например WordPad), а не текстовой процессор (word processor). Дело в том, что при вводе текста программ должны быть созданы исключительно текстовые файлы, а не файлы, в которых вместе с текстом сохраняется информация о его форматировании. Помните, что информация о форматировании помешает работе С++-компилятора. Имя файла, который будет содержать исходный код программы, формально может быть любым. Но С++-программы обычно хранятся в файлах с расширением .срр . Поэтому называйте свои С++-программы любыми именами, но в качестве расширения используйте .срр . Например, назовите нашу первую программу MyProg.cpp (это имя будет употребляться в дальнейших инструкциях), а для других программ (если не будет специальных указаний) выбирайте имена по своему усмотрению.Компилирование программы
Способ компиляции программы MyProg.срр зависит от используемого компилятора и выбранных опций. Более того, многие компиляторы, например Visual C++ (Microsoft) и C++ Builder (Borland), предоставляют два различных способа компиляции программ: с помощью компилятора командной строки и интегрированной среды разработки (Integrated Development Environment — IDE). Поэтому для компилирования С++-программ невозможно дать универсальные инструкции, которые подойдут для всех компиляторов. Это значит, что вы должны следовать инструкциям, приведенным в сопроводительной документации, прилагаемой к вашему компилятору. Но, как упоминалось выше, самыми популярными компиляторами являются Visual C++ и C++ Builder, поэтому для удобства читателей, которые их используют, мы приведем здесь инструкции по компиляции программ, соответствующие этим компиляторам. Проще всего в обоих случаях компилировать и выполнять программы, приведенные в этой книге, с использованием компиляторов командной строки. Так мы и поступим. Чтобы скомпилировать программу МуРrog.срр, используя Visual C++, введите следующую командную строку:C:\...>cl -GX MyProg.cpp
Опция -GX предназначена для повышения качества компиляции. Чтобы использовать компилятор командной строки Visual C++, необходимо выполнить пакетный файл VCVARS32.bat, который входит в состав Visual C++.
Чтобы скомпилировать программу MyProg.срр, используя C++ Builder, введите такую командную строку:
С: \...>bcc32 MyProg.срр
В результате работы С++-компилятора получается выполняемый объектный код. Для Windows-среды выполняемый файл будет иметь то же имя, что и исходный, но другое расширение, а именно расширение .ехе. Итак, выполняемая версия программы MyProg.срр будет храниться в файле MyProg.ехе.
На заметку. Если при попытке скомпилировать первую программу вы получили сообщение об ошибке, но уверены, что ввели ее текст корректно, то, возможно, вы используете старую версию С++-компилятора, который был создан до принятия С++-стандарта ANSI/ISO. В этом случае обратитесь к приложению Б за инструкциями по использованию старых компиляторов.
Выполнение программы
Скомпилированная программа готова к выполнению. Поскольку результатом работы - С++-компилятора является выполняемый объектный код, то для запуска программы в качестве команды достаточно ввести ее имя. Например, чтобы выполнить программу MyProg.ехе, используйте эту командную строку:С:\...>MyProg.срр
Результаты выполнения этой программы таковы:
Это моя первая С++-программа.
Если вы используете интегрированную среду разработки, то выполнить программу можно путем выбора из меню команды Run (Выполнить). Безусловно, более точные инструкции приведены в сопроводительной документации, прилагаемой к вашему компилятору. Но, как упоминалось выше, проще всего компилировать и выполнять приведенные в этой книге программы с помощью командной строки.
Необходимо отметить, что все эти программы представляют собой консольные приложения, а не приложения, основанные на применении окон, т.е. они выполняются в сеансе приглашения на ввод команды. При этом вам, должно быть, известно, что язык С++ не просто подходит для Windows-программирования, C++ — основной язык, применяемый в разработке Windows-приложений. Однако ни одна из программ, представленных в этой книге, не использует графического интерфейса пользователя (GUI — graphics use interface). Дело в том, что Windows — довольно сложная среда для написания программ включающая множество второстепенных тем, не связанных напрямую с языком C++ В то же время консольные приложения гораздо короче графических и лучше подходят для обучения программированию. Освоив C++, вы сможете без проблем применить свои знания в сфере создания Windows-приложений.
Построчный "разбор полетов"
После успешной компиляции и выполнения первого примера программы настало время разобраться в том, как она работает. Поэтому мы подробно рассмотрим каждую её строку. Итак, наша программа начинается с таких строк./* Программа №1 - Первая С++-программа.
Введите эту программу, затем скомпилируйте ее и выполните.
*/
Это — комментарий. Подобно большинству других языков программирования, C++ позволяет вводить в исходный код программы комментарии, содержание которых компилятор игнорирует. С помощью комментариев описываются или разъясняются действия, выполняемые в программе, и эти разъяснения предназначаются для тех, кто будет читать исходный код. В данном случае комментарий просто идентифицирует программу и напоминает, что с ней нужно сделать. Конечно, в реальных приложениях комментарии используются для разъяснения особенностей работы отдельных частей программы или конкретных действий программных средств. Другими словами, вы можете использовать комментарии для детального описания всех (или некоторых) ее строк.
Комментарий — это текст пояснительного содержания, встраиваемый в программу.
В C++ поддерживается два типа комментариев. Первый, показанный в начале рассматриваемой программы, называется многострочным. Комментарий этого типа должен начинаться символами /* и заканчиваться ими же, но переставленными в обратном порядке (*/). Все, что находится между этими парами символов, компилятор игнорирует. Комментарий этого типа, как следует из его названия, может занимать несколько строк. Второй тип комментариев мы рассмотрим чуть ниже.
Приведем здесь следующую строку программы.
#include <iostream>
В языке C++ определен ряд заголовков (header), которые обычно содержат информацию, необходимую для программы. В нашу программу включен заголовок <iostream> (он используется для поддержки в С++-системы ввода-вывода), который представляет собой внешний исходный файл, помещаемый компилятором в начало программы с помощью директивы #include. Ниже в этой книге мы ближе познакомимся с заголовками и узнаем, почему они так важны.
Рассмотрим следующую строку программы:
using namespace std;
Эта строка означает, что компилятор должен использовать пространство имен std. Пространства имен — относительно недавнее дополнение к языку C++. Подробнее о них мы поговорим позже, а пока ограничимся их кратким определением. Пространство имен (namespace) создает декларативную область, в которой могут размещаться различные элементы программы. Пространство имен позволяет хранить одно множество имен отдельно от другого. Другими словами, имена, объявленные в одном пространстве имен, не будут конфликтовать с такими же именами, объявленными в другом. Пространства имен позволяют упростить организацию больших программ. Ключевое слово using информирует компилятор об использовании заявленного пространства имен (в данном случае std). Именно в пространстве имен std объявлена вся библиотека стандарта C++. Таким образом, используя пространство имен std, вы упрощаете доступ к стандартной библиотеке языка.
Очередная строка в нашей программе представляет собой однострочный комментарий.
// main() - начало выполнения программы.
Так выглядит комментарий второго типа, поддерживаемый в C++. Однострочный комментарий начинается с пары символов // и заканчивается в конце строки. Как правило, программисты используют многострочные комментарии для подробных и потому более пространных разъяснений, а однострочные — для кратких (построчных) описаний инструкций или назначения переменных. Вообще-то, характер использования комментариев — личное дело программиста.
Перейдем к следующей строке:
int main()
Как сообщается в только что рассмотренном комментарии, именно с этой строки и начинается выполнение программы.
С функции main() начинается выполнение любой С++-программы.
Все С++-программы состоят из одной или нескольких функций. (Под функцией main понимаем подпрограмму.) Каждая С++-функция имеет имя, и только одна из них (её должна включать каждая С++-программа) называется main(). Выполнение C++ программы начинается и заканчивается (в большинстве случаев) выполнением функции main(). (Точнее, С++-программа начинается с вызова функции main() и обычно заканчивается возвратом из функции main().) Открытая фигурная скобка на следующей (после int main()) строке указывает на начало кода функции main(). Ключевое слово int (сокращение от слова integer), стоящее перед именем main(), означает тип данных для значения, возвращаемого функцией main(). Как вы скоро узнаете, C++ поддерживает несколько встроенных типов данных, и int — один из них.
Рассмотрим очередную строку программы:
cout << "Это моя первая С++-программа.";
Это инструкция вывода данных на консоль. При ее выполнении на экране компьютера отобразится сообщение Это моя первая С++-программа.. В этой инструкции используется оператор вывода "<<". Он обеспечивает вывод выражения, стоящего с правой стороны, на устройство, указанное с левой. Слово cout представляет собой встроенный идентификатор (составленный из частей слов console output), который в большинстве случаев означает экран компьютера. Итак, рассматриваемая инструкции обеспечивает вывод заданного сообщения на экран. Обратите внимание на то, что эта инструкция завершается точкой с запятой. В действительности все выполняемые С++-инструкции завершаются точкой с запятой.
Сообщение "Это моя первая С++-программа." представляет собой строку В C++ под строкой понимается последовательность символов, заключенная в двойные кавычки. Как вы увидите, строка в C++ — это один из часто используемых элементов языка.
А этой строкой завершается функция main():
return 0;
При ее выполнении функция main() возвращает вызывающему процессу (в роли которого обычно выступает операционная система) значение 0. Для большинства операционных систем нулевое значение, которое возвращает эта функция, свидетельствует о нормальном завершении программы. Другие значения могут означать завершение программы в связи с какой-нибудь ошибкой. Слово return относится к числу ключевых используется для возврата значения из функции. При нормальном завершении (т.е. без ошибок) все ваши программы должны возвращать значение 0.
Закрывающая фигурная скобка в конце программы формально завершает ее. Хотя фигурная скобка в действительности не является частью объектного кода программы, её "выполнение" (т.е. обработку закрывающей фигурной скобки функции main()) мысленно можно считать концом С++-программы. И в самом деле, если в этом примере программы инструкция return отсутствовала бы, программа автоматически завершилась бы по достижении этой закрывающей фигурной скобки.
Обработка синтаксических ошибок
Каждому программисту известно, насколько легко при вводе текста программы в компьютер вносятся случайные ошибки (опечатки). К счастью, при попытке скомпилировать такую программу компилятор "просигналит" сообщением о наличии синтаксических ошибок. Большинство С++-компиляторов попытаются "увидеть" смысл в исходном коде программы, независимо от того, что вы ввели. Поэтому сообщение об ошибке не всегда отражает истинную причину проблемы. Например, если в предыдущей программе случайно опустить открывающую фигурную скобку после имени функции main(), компилятор укажет в качестве источника ошибки инструкцию cout. Поэтому при получении сообщения об ошибке просмотрите две-три строки кода, непосредственно предшествующих строке с "обнаруженной" ошибкой. Ведь иногда компилятор начинает "чуять недоброе" только через несколько строк после реального местоположения ошибки. Многие С++-компиляторы выдают в качестве результатов своей работы не только сообщения об ошибках, но и предупреждения (warning). В язык C++ "от рождения" заложено великодушное отношение к программисту, т.е. он позволяет программисту практически все, что корректно с точки зрения синтаксиса. Однако даже "всепрощающим" С++-компиляторам некоторые синтаксически правильные вещи могут показаться подозрительными. В таких ситуациях и выдается предупреждение. Тогда программист сам должен оценить, насколько справедливы подозрения компилятора. Откровенно говоря, некоторые компиляторы слишком уж бдительны и предупреждают по поводу совершенно корректных инструкций. Кроме того, компиляторы позволяют использовать различные опции, которые могут информировать об интересующих вас вещах. Иногда такая информация имеет форму предупреждающего сообщения даже несмотря на отсутствие "состава" предупреждения. Программы, приведенные в этой книге, написаны в соответствии со стандартом C++ и при корректном вводе не должны генерировать никаких предупреждающих сообщений. Важно! Большинство С++-компиляторов предлагают несколько уровней сообщений (и предупреждений) об ошибках. В общем случае можно выбрать тип ошибок, о наличии которых вы хотели бы получать сообщения. Например, большинство компиляторов по желанию программиста могут информировать об использовании неэффективных конструкций или устаревших средств. Для примеров этой книги достаточно использовать обычную настройку компилятора. Но вам все же имеет смысл заглянуть в прилагаемую к компилятору документацию и поинтересоваться, какие возможности по управлению процессом компиляции есть в вашем распоряжении. Многие компиляторы довольно "интеллектуальны" и могут помочь в обнаружении неочевидных ошибок еще до того, как они перерастут в большие проблемы. Знание принципов, используемых компилятором при составлении отчета об ошибках, стоит затрат времени и усилий, которые потребуются от программиста на их освоение.Вторая С++-программа
Возможно, самой важной конструкцией в любом языке программирования является присвоение переменной некоторого значения. Переменная — это именованная область памяти, в которой могут храниться различные значения. При этом значение переменной во время выполнения программы можно изменить один или несколько раз. Другими словами, содержимое переменной изменяемо, а не фиксированно. В следующей программе создается переменная с именем х, которой присваивается значение 1023, а затем на экране отображается сообщение Эта программа выводит значение переменной х: 1023.// Программа №2 - Использование переменной.
#include <iostream>
using namespace std;
int main()
{
int x; // Здесь объявляется переменная.
x = 1023; // Здесь переменной х присваивается число 1023.
cout << "Эта программа выводит значение переменной х: ";
cout << х; // Отображение числа 1023.
return 0;
}
Что же нового в этой программе? Во-первых, инструкция:
int х; // Здесь объявляется переменная.
объявляет переменную с именем х целочисленного типа. В C++ все переменные должны быть объявлены до их использования. В объявлении переменной помимо ее имени необходимо указать, значения какого типа она может хранить. Тем самым объявляется тип переменной. В данном случае переменная х может хранить целочисленные значения, т.е. целые числа, лежащие в диапазоне -32 768--32 767. В C++ для объявления переменной целочисленного типа достаточно поставить перед ее именем ключевое слово int. Таким образом, инструкция int х; объявляет переменную х типа int. Ниже вы узнаете, что C++ поддерживает широкий диапазон встроенных типов переменных. (Более того, C++ позволяет программисту определять собственные типы данных.)
Во-вторых, при выполнении следующей инструкции переменной присваивается конкретное значение:
х = 1023; // Здесь переменной х присваивается число 1023.
В C++ оператор присваивания представляется одиночным знаком равенства (=). Его действие заключается в копировании значения, расположенного справа от оператора, в переменную, указанную слева от него. После выполнения этой инструкции присваивания переменная x будет содержать число 1023.
Результаты, сгенерированные этой программой, отображаются на экране с помощью двух инструкций cout. Обратите внимание на использование следующей инструкции для вывода значения переменной x:
cout << х; // Отображение числа 1023.
В общем случае для отображения значения переменной достаточно в инструкции cout поместить ее имя справа от оператора "<<". Поскольку в данном конкретном случае переменная x содержит число 1023, то оно и будет отображено на экране. Прежде чем переходить к следующему разделу, попробуйте присвоить переменной х другие значения (в исходном коде) и посмотрите на результаты выполнения этой программы после внесения изменений.
Более реальный пример
Первые две программы, кроме демонстрации ряда важных средств языка C++, не делали ничего полезного. В следующей программе решается практическая задача преобразования галлонов в литры. Здесь также показан один из способов ввода данных в программу.// Эта программа преобразует галлоны в литры.
#include <iostream>
using namespace std;
int main()
{
int gallons, liters;
cout << "Введите количество галлонов:";
cin >> gallons; // Ввод данных от пользователя.
liters = gallons * 4; // Преобразование в литры.
cout << "Литров: " << liters;
return 0;
}
Эта программа сначала отображает на экране сообщение, предлагающее пользователю ввести число для преобразования галлонов в литры, а затем ожидает до тех пор, пока оно не будет введено. (Помните, вы должны ввести целое число галлонов, т.е. число, не содержащее дробной части.) Затем программа отобразит значение, приблизительно равное эквивалентному объему, выраженному в литрах. В действительности для получения точного результата необходимо использовать коэффициент 3,7854 (т.е. в одном галлоне помещается 3,7854 литра), но поскольку в этом примере мы работаем с целочисленными переменными, то коэффициент преобразования округлен до 4.
Обратите внимание на то, что две переменные gallons и liters объявляются после ключевого слова int в форме списка, элементы которого разделяются запятыми. В общем случае можно объявить любое количество переменных одного типа, разделив их запятыми. (В качестве альтернативного варианта можно использовать несколько декларативных int-инструкций — результат будет тот же.)
Для приема значения, вводимого пользователем, используется следующая инструкция:
cin >> gallons; // Ввод данных от пользователя.
Здесь применяется еще один встроенный идентификатор — cin — предоставляемый С++-компилятором. Он составлен из частей слов console input и в большинстве случаев означает ввод данных с клавиатуры. В качестве оператора ввода используется символ ">>". При выполнении этой инструкции значение, введенное пользователем (которое в данном случае должно быть целочисленным), помещается в переменную, указанную с правой стороны от оператора ">>" (в данном случае это переменная gallons).
В этой программе заслуживает внимания и эта инструкция:
cout << "Литров: " << liters;
Здесь интересно то, что в одной инструкции использовано сразу два оператора вывода "<<". При ее выполнении сначала будет выведена строка "Литров: ", а за ней — значение переменной liters. В общем случае в одной инструкции Можно соединять любое количество операторов вывода, предварив каждый элемент вывода "своим" оператором
Новый тип данных
Несмотря на то что для приблизительных подсчетов вполне сгодится рассмотренная выше программа преобразования галлонов в литры, для получения более точных результатов ее необходимо переделать. Как отмечено выше, с помощью целочисленных типов данных невозможно представить значения с дробной частью. Для них нужно использовать один из типов данных с плавающей точкой, например double (двойной точности). Данные этого типа обычно находятся в диапазоне 1,7Е-308--1,7Е+308. Операции, вы-полняемые над числами с плавающей точкой, сохраняют любую дробную часть результата и, следовательно, обеспечивают более точное преобразование. В следующей версии программы преобразования используются значения с плавающей точкой./* Эта программа преобразует галлоны в литры с помощью чисел с плавающей точкой.
*/
#include <iostream>
using namespace std;
int main()
{
double gallons, liters;
cout << "Введите количество галлонов: ";
cin >> gallons; // Ввод данных от пользователя.
liters = gallons * 3.7854; // Преобразование в литры.
cout << "Литров: " << liters;
return 0;
}
Для получения этого варианта в предыдущую программу было внесено два изменения. Во-первых, переменные gallons и liters объявлены на этот раз с использованием типа double. Во-вторых, коэффициент преобразования задан в виде числа 3.7854, что позволяет получить более точные результаты. Если С++-компилятор встречает число, содержащее десятичную точку, он автоматически воспринимает его как константу с плавающей точкой. Обратите также внимание на то, что инструкции cout и cin остались такими же, как в предыдущем варианте программы, в которой использовались переменные типа int. Это очень важный момент: С++-система ввода-вывода автоматически настраивается на тип данных, указанный в программе.
Скомпилируйте и выполните эту программу. На приглашение указать количество галлонов введите число 1. В качестве результата программа должна отобразить 3,7854 литра.
Повторим пройденное
Итак, подытожим самое важное из уже прочитанного материала. 1. Каждая С++-программа должна иметь функцию main(), которая означает начало выполнения программы. 2. Все переменные должны быть объявлены до их использования. 3. C++ поддерживает различные типы данных, включая целочисленные и с плавающей точкой. 4. Оператор вывода данных обозначается символом "<<", а при использовании в инструкции cout он обеспечивает отображение информации на экране компьютера. 5. Оператор ввода данных обозначается символом ">>", а при использовании в инструкции cin он считывает информацию с клавиатуры. 6. Выполнение программы завершается с окончанием функции main().Функции
Любая С++-программа составляется из "строительных блоков", именуемых функциями. Функция — это подпрограмма, которая содержит одну или несколько С++-инструкий и выполняет одну или несколько задач. Хороший стиль программирования на C++ предполагает, что каждая функция выполняет только одну задачу. Каждая функция имеет имя, которое используется для ее вызова. Своим функциям программист может давать любые имена за исключением имени main(), зарезервированного для функции, с которой начинается выполнение программы. Функции — это "строительные блоки" С++-программы. В C++ ни одна функция не может быть встроена в другую. В отличие от таких языков программирования, как Pascal, Modula-2 и некоторых других, которые позволяют использование вложенных функций, в C++ все функции рассматриваются как отдельные компоненты. (Безусловно, одна функция может вызывать другую.) При обозначении функций в тексте этой книги используется соглашение (обычно соблюдаемое в литературе, посвященной языку программирования C++), согласно которому имя функции завершается парой круглых скобок. Например, если функция имеет имя getval, то ее упоминание в тексте обозначится как getval(). Соблюдение этого соглашения позволит легко отличать имена переменных от имен функций. В уже рассмотренных примерах программ функция main() была единственной. Как упоминалось выше, функция main() — первая функция, выполняемая при запуске программы. Ее должна содержать каждая С++-программа. Вообще, функции, которые вам предстоит использовать, бывают двух типов. К первому типу относятся функции, написанные программистом (main() — пример функции такого типа). Функции другого типа находятся в стандартной библиотеке С++-компилятора. (Стандартная библиотека будет рассмотрена ниже, а пока заметим, что она представляет собой коллекцию встроенных функций.) Как правило, С++-программы содержат как функции, написанные программистом, так и функции, предоставляемые компилятором. Поскольку функции образуют фундамент C++, займемся ими вплотную.Программа с двумя функциями
Следующая программа содержит две функции: main() и myfunc(). Еще до выполнения этой программы (или чтения последующего описания) внимательно изучите ее текст и попытайтесь предугадать, что она должна отобразить на экране./* Эта программа содержит две функции: main() и myfunc().
*/
#include <iostream>
using namespace std;
void myfunc(); // прототип функции myfunc()
int main()
{
cout << "В функции main().";
myfunc(); // Вызываем функцию myfunc().
cout << "Снова в функции main().";
return 0;
}
void myfunc() {
cout << " В функции myfunc(). ";
}
Программа работает следующим образом. Вызывается функция main() и выполняется ее первая cout-инструкция. Затем из функции main() вызывается функция myfunc(). Обратите внимание на то, как этот вызов реализуется в программе: указывается имя функции myfunc, за которым следуют пара круглых скобок и точка с запятой. Вызов любой функции представляет собой С++-инструкцию и поэтому должен завершаться точкой с запятой. Затем функция myfunc() выполняет свою единственную cout-инструкцию и передает управление назад функции main(), причем той строке кода, которая расположена непосредственно за вызовом функции. Наконец, функция main() выполняет свою вторую cout-инструкцию, которая завершает всю программу. Итак, на экране мы должны увидеть такие результаты.
В функции main().
В функции myfunc().
Снова в функции main().
В этой программе необходимо рассмотреть следующую инструкцию.
void myfunc(); // прототип функции myfunc()
Прототип объявляет функцию до ее первого использования.
Как отмечено в комментарии, это — прототип функции myfunc(). Хотя подробнее прототипы будут рассмотрена ниже, все же без кратких пояснений здесь не обойтись. Прототип функции объявляет функцию до ее определения. Прототип позволяет компилятору узнать тип значения, возвращаемого этой функцией, а также количество и тип парамeтров, которые она может иметь. Компилятору нужно знать эту информацию до первого вызова функции. Поэтому прототип располагается до функции main(). Единственной функцией, которая не требует прототипа, является main(), поскольку она встроена в язык C++.
Как видите, функция myfunc() не содержит инструкцию return. Ключевое слово void, которое предваряет как прототип, так и определение функции myfunc(), формально заявляет о том, что функция myfunc() не возвращает никакого значения. В C++ функции, не возвращающие значений, объявляются с использованием ключевого слова void.
Аргументы функций
Функции можно передать одно или несколько значений. Значение, передаваемое функции, называется аргументом. Несмотря на то что в программах, которые мы рассматривали до сих пор, ни одна из функций (ни main(), ни myfunc()) не принимала никаких значений, функции в C++ могут принимать один или несколько аргументов. Верхний предел числа принимаемых аргументов определяется конкретным компилятором. Согласно стандарту C++ он равен 256. Аргумент — это значение, передаваемое функции при вызове. Рассмотрим короткую программу, которая для отображения абсолютного значения числа использует стандартную библиотечную (т.е. встроенную) функцию abs(). Эта функция принимает один аргумент, преобразует его в абсолютное значение и возвращает результат.// Использование функции abs().
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
cout << abs(-10);
return 0;
}
Здесь функции abs() в качестве аргумента передается число -10. Функция abs() принимает этот аргумент при вызове и возвращает его абсолютное значение, которое в свою очередь передаётся инструкции cout для отображения на экране абсолютного значения числа -10. Дело в том, что если функция является частью выражения, она автоматически вызывается для получения возвращаемого ею значения. В данном случае значение, возвращаемое функцией abs(), оказывается справа от оператора "<<" и поэтому законно отображается на экране.
Обратите также внимание на то, что рассматриваемая программа включает заголовок <cstdlib>. Этот заголовок необходим для обеспечения возможности вызова функции abs(). Каждый раз, когда вы используете библиотечную функцию, в программу необходимо включать соответствующий заголовок. Заголовок, помимо прочей информации, содержит прототип библиотечной функции.
Параметр — это определяемая функцией переменная, которая принимает передаваемый функции аргумент.
При создании функции, которая принимает один или несколько аргументов, иногда необходимо объявить переменные, которые будут хранить значения аргументов. Эти переменные называются параметрами функции. Например, следующая функция выводит произведение двух целочисленных аргументов, передаваемых функции при ее вызове.
void mul (int х, int у)
{
cout << х * у << " ";
}
При каждом вызове функции mul() выполняется умножение значения, переданного параметру х, на значение, переданное параметру у. Однако помните, что х и у — это просто переменные, которые принимают значения, передаваемые при вызове функции.
Рассмотрим следующую короткую программу, которая демонстрирует использование функции mul().
// Простая программа, которая демонстрирует использование функции mul().
#include <iostream>
using namespace std;
void mul(int x, int у); // Прототип функции mul().
int main()
{
mul (10, 20);
mul (5, 6);
mul (8, 9);
return 0;
}
void mul(int x, int y)
{
cout << x * у << " ";
}
Эта программа выведет на экран числа 200, 30 и 72. При вызове функции mul() С++-компилятор копирует значение каждого аргумента в соответствующий параметр. В данном случае при первом вызове функции mul() число 10 копируется в переменную х, а число 20 — в переменную у. При втором вызове 5 копируется в х, а 6 — в у. При третьем вызове 8 копируется в х, а 9 — в у.
Если вы никогда не работали с языком программирования, в котором разрешены параметризованные функции, описанный процесс может показаться несколько странным. Однако волноваться не стонт: по мере рассмотрения других С++-программ принцип использования функций, их аргументов и параметров станет более понятным.
Узелок на память. Термин аргумент относится к значению, которое используется при вызове функции. Переменная, которая принимает этот аргумент, называется параметром. Функции, которые принимают аргументы, называются параметризованными функциями.
Если С++-функции имеют два или больше аргументов, то они разделяются запятыми. В этой книге под термином список аргументов следует понимать аргументы, разделенные запятыми. Для рассмотренной выше функции mul() список аргументов выражен в виде x, у.
Функции, возвращающие значения
В C++ многие библиотечные функции возвращают значения. Например, уже знакомая вам функция abs() возвращает абсолютное значение своего аргумента. Функции, написанные программистом, также могут возвращать значения. В C++ для возврата значения используется инструкция return. Общий формат этой инструкции таков:return значение;
Нетрудно догадаться, что здесь элемент значение представляет собой значение, возвращаемое функцией.
Чтобы продемонстрировать процесс возврата функциями значений, переделаем предыдущую программу так, как показано ниже. В этой версии функция mul() возвращает произведение своих аргументов. Обратите внимание на то, что расположение функции справа от оператора присваивания означает присваивание переменной (расположенной слева) значения, возвращаемого этой функцией.
// Демонстрация возврата функциями значений.
#include <iostream>
using namespace std;
int mul (int x, int у); // Прототип функции mul().
int main()
{
int answer;
answer = mul (10, 11); // Присваивание значения, возвращаемого функцией.
cout << "Ответ равен" << answer;
return 0;
}
// Эта функция возвращает значение.
int mul (int х, int у)
{
return х * у; // Функция возвращает произведение х и у.
}
В этом примере функция mul() возвращает результат вычисления выражения х*у с помощью инструкции return. Затем значение этого результата присваивается переменной answer. Таким образом, значение, возвращаемое инструкцией return, становится значением функции mul() в вызывающей программе.
Поскольку в этой версии программы функция mul() возвращает значение, ее имя в определении не предваряется словом void. (Вспомните, слово void используется только в том случае, когда функция не возвращает никакого значения.) Поскольку существуют различные типы переменных, существуют и различные типы значений, возвращаемых функциями. Здесь функция mul() возвращает значение целочисленного типа. Тип значения, возвращаемого функцией, предшествует ее имени как в прототипе, так и в определении.
В более ранних версиях C++ для типов значений, возвращаемых функциями, существовало соглашение, действующее по умолчанию. Если тип возвращаемого функцией значения не указан, предполагалось, что эта функция возвращает целочисленное значение. Например, функция mul() согласно тому соглашению могла быть записана так.
// Устаревший способ записи функции mul().
mul (int X, int у) /* По умолчанию в качестве типа значения, возвращаемого функцией, используется тип int.*/
{
return х * у; // Функция возвращает произведение х и у.
}
Здесь по умолчанию предполагается целочисленный тип значения, возвращаемого функцией, поскольку не задан никакой другой тип. Однако правило установки целочисленного типа по умолчанию было отвергнуто стандартом C++. Несмотря на то что большинство компиляторов поддерживают это правило ради обратной совместимости, вы должны явно задавать тип значения, возвращаемого каждой функцией, которую пишете. Но если вам придется разбираться в старых версиях С++-программ, это соглашение следует иметь в виду.
При достижении инструкции return функция немедленно завершается, а весь остальной код игнорируется. Функция может содержать несколько инструкций return. Возврат из функции можно обеспечить с помощью инструкции return без указания возвращаемого значения, но такую ее форму допустимо применять только для функций, которые не возвращают никаких значений и объявлены с использованием ключевого слова void.
Функция main()
Как вы уже знаете, функция main() — специальная, поскольку это первая функция которая вызывается при выполнении программы. В отличие от некоторых других языков программирования, в которых выполнение всегда начинается "сверху", т.е. с первой строки кода, каждая С++-программа всегда начинается с вызова функции main() независимо от ее расположения в программе. (Все же обычно функцию main() размещают первой, чтобы ее было легко найти.) В программе может быть только одна функция main(). Если попытаться включить в программу несколько функций main(), она "не будет знать", с какой из них начать работу. В действительности большинство компиляторов легко обнаружат ошибку этого типа и сообщат о ней. Как упоминалось выше, поскольку функция main() встроена в язык C++, она не требует прототипа.Общий формат С++-функций
В предыдущих примерах были показаны конкретные типы функций. Однако все С++-функции имеют такой общий формат.тип_возвращаемого_значения имя (список_параметров) {
.
.// тело метода
.
}
Рассмотрим подробно все элементы, составляющие функцию.
С помощью элемента тип_возвращаемого_значения указывается тип значения, возвращаемого функцией. Как будет показано ниже в этой книге, это может быть практически любой тип, включая типы, создаваемые программистом. Если функция не возвращает никакого значения, необходимо указать тип void. Если функция действительно возвращает значение, оно должно иметь тип, совместимый с указанным в определении функции.
Каждая функция имеет имя. Оно, как нетрудно догадаться, задается элементом имя. После имени функции между круглых скобок указывается список параметров, который представляет собой последовательность пар (состоящих из типа данных и имени), разделенных запятыми. Если функция не имеет параметров, элемент список_параметров отсутствует, т.е. круглые скобки остаются пустыми.
В фигурные скобки заключено тело функции. Тело функции составляют С++-инструкции, которые определяют действия функции. Функция завершается (и управление передается вызывающей процедуре) при достижении закрывающей фигурной скобки или инструкции return.
Некоторые возможности вывода данных
До сих пор у нас не было потребности при выводе данных обеспечивать переход на следующую строку. Однако такая необходимость может потребоваться очень скоро. В C++ последовательность символов "возврат каретки/перевод строки" генерируется с помощью символа новой строки. Для вывода этого символа используется такой код: \n (символ обратной косой черты и строчная буква n). Продемонстрируем использование последовательности символов "возврат каретки/перевод строки" на примере следующей программы./* Эта программа демонстрирует \n-последовательность, которая обеспечивает переход на новую строку.
*/
#include <iostream>
using namespace std;
int main()
{
cout << "один\n";
cout << "два\n";
cout << "три";
cout << "четыре";
return 0;
}
При выполнении программа генерирует такие результаты:
один
два
тричетыре
Символ новой строки можно поместить в любом месте строки, а не только в конце. "Поиграйте" с символом новой строки, чтобы убедиться в том, что вы правильно понимаете его назначение.
Две простые инструкции
Для рассмотрения более реальных примеров программ нам необходимо познакомиться с двумя С++-инструкциями: if и for. (Более подробное их описание приведено ниже в этой книге.)Инструкция if
Инструкция if позволяет сделать выбор между двумя выполняемыми ветвями программы. Инструкция if в C++ действует подобно инструкции IF, определенной в любом другом языке программирования. Её простейший формат таков:if(условие) инструкция;
Здесь элемент условие — это выражение, которое при вычислении может оказаться равным значению ИСТИНА или ЛОЖЬ. В C++ ИСТИНА представляется ненулевым значением, а ЛОЖЬ — нулем. Если условие, или условное выражение, истинно, элемент инструкция выполнится, в противном случае — нет. При выполнении следующего фрагмента кода на экране отобразится фраза 10 меньше 11.
if(10 < 11) cout << "10 меньше 11";
Такие операторы сравнения, как "<" (меньше) и ">=" (больше или равно), используются во многих других языках программирования. Но следует помнить, что в C++ в качестве оператора равенства применяется двойной символ "равно" (==). В следующем примере cout-инструкция не выполнится, поскольку условное выражение дает значение ЛОЖЬ. Другими словами, поскольку 10 не равно 11, cout-инструкция не отобразит на экране приветствие.
if(10==11) cout << "Привет";
Безусловно, операнды условного выражения необязательно должны быть константами. Они могут быть переменными и даже содержать обращения к функциям.
В следующей программе показан пример использования if-инструкции. При выполнении этой программы пользователю предлагается ввести два числа, а затем сообщается результат их сравнения.
// Эта программа демонстрирует использование if-инструкции.
#include <iostream>
using namespace std;
int main()
{
int a,b;
cout << "Введите первое число: ";
cin >> a;
cout << "Введите второе число: ";
cin >> b;
if(a < b) cout << "Первое число меньше второго.";
return 0;
}
Цикл for
for — одна из циклических инструкций, определенных в C++. Цикл for повторяет указанную инструкцию заданное число раз. Инструкция for в C++ действует практически так же, как инструкция FOR, определенная в таких языках программирования, как Java, С#, Pascal и BASIC. Ее простейший формат таков:for(инициализация; условие; инкремент) инструкция;
Здесь элемент инициализация представляет собой инструкцию присваивания, которая устанавливает управляющую переменную цикла равной начальному значению. Эта переменная действует в качестве счетчика, который управляет работой цикла. Элемент условие представляет собой выражение, в котором тестируется значение управляющей переменной цикла. Результат этого тестирования определяет, выполнится цикл for еще раз или нет. Элемент инкремент — это выражение, которое определяет, как изменяется значение управляющей переменной цикла после каждой итерации. Цикл for будет выполняться до тех пор, пока вычисление элемента условие дает истинный результат. Как только условие станет ложным, выполнение программы продолжится с инструкции, следующей за циклом for.
Например, следующая программа с помощью цикла for выводит на экран числа от 1 до 100.
// Программа демонстрирует использование for-цикла.
#include <iostream>
using namespace std;
int main()
{
int count;
for(count=1; count<=100; count=count+1)
cout << count << " ";
return 0;
}
На рис. 2.1 схематично показано выполнение цикла for в этом примере. Как видите, сначала переменная count инициализируется числом 1. При каждом повторении цикла проверяется условие count<=100. Если результат проверки оказывается истинным, cout-инструкция выводит значение переменной count, после чего ее содержимое увеличивается на единицу. Когда значение переменной count превысит 100, проверяемое условие даст в результате ЛОЖЬ, и выполнение цикла прекратится.
В профессионально написанном С++-коде редко можно встретить инструкцию count=count+1, поскольку для инструкций такого рода в C++ предусмотрена специальная сокращенная форма: count++. Оператор "++" называется оператором инкремента. Он увеличивает операнд на единицу. Оператор "++" дополняется оператором "--" (оператором декремента), который уменьшает операнд на единицу. С помощью оператора инкремента используемую в предыдущей программе инструкцию for можно переписать следующим образом.
for(count=1; count<=100; count++) cout << count << " ";

Блоки кода
Поскольку C++ — структурированный (а также объектно-ориентированный) язык, он поддерживает создание блоков кода. Блок — это логически связанная группа программных инструкций, которые обрабатываются как единое целое. В C++ программный блок создается путем размещения последовательности инструкций между фигурными (открывающей и закрывающей) скобками. В следующем примереif(х<10) {
cout << "Слишком мало, попытайтесь еще раз.";
cin >> х;
}
обе инструкции, расположенные после if-инструкции (между фигурными скобками) выполнятся только в том случае, если значение переменной х меньше 10. Эти две инструкции (вместе с фигурными скобками) представляют блок кода. Они составляют логически неделимую группу: ни одна из этих инструкций не может выполниться без другой. С использованием блоков кода многие алгоритмы реализуются более четко и эффективно. Они также позволяют лучше понять истинную природу алгоритмов.
Блок — это набор логически связанных инструкций.
В следующей программе используется блок кода. Введите эту программу и выполните ее, и тогда вы поймете, как работает блок кода.
// Программа демонстрирует использование блока кода.
#include <iostream>
using namespace std;
int main()
{
int a, b;
cout << "Введите первое число: "; cin >> a;
cout << "Введите второе число: "; cin >> b;
if(a < b) {
cout << "Первое число меньше второго.\n";
cout << "Их разность равна: " << b-a;
}
return 0;
}
Эта программа предлагает пользователю ввести два числа с клавиатуры. Если первое число меньше второго, будут выполнены обе cout-инструкцин. В противном случае обе они будут опущены. Ни при каких условиях не выполнится только одна из них.
Точки с запятой и расположение инструкции
В C++ точка с запятой означает конец инструкции. Другими словами, каждая отдельная инструкция должна завершаться точкой с запятой. Как вы знаете, блок — это набор логически связанных инструкций, которые заключены между открывающей и закрывающей фигурными скобками. Блок нe завершается точкой с запятой. Поскольку блок состоит из инструкций, каждая из которых завершается точкой с запятой, то в дополнительной точке с запятой нет никакого смысла. Признаком же конца блока служит закрывающая фигурная скобка (зачем еще один признак?). Язык C++ не воспринимает конец строки в качестве признака конца инструкции. По-этому для компилятора не имеет значения, в каком месте строки располагается инструкция. Например, с точки зрения С++-компилятора, следующий фрагмент кодах = у;
у = у+1;
mul(x, у);
аналогичен такой строке:
x = у; у = у+1; mul(x, у);
Практика отступов
Рассматривая предыдущие примеры, вы, вероятно, заметили, что некоторые инструкции сдвинуты относительно левого края. C++ — язык свободной формы, т.е. его синтаксис не связан позиционными или форматными ограничениями. Это означает, что для С++-компилятора не важно, как будут расположены инструкции по отношению друг к другу. Но у программистов с годами выработался стиль применения отступов, который значительно повышает читабельность программ. В этой книге мы придерживаемся этого стиля и вам советуем поступать так же. Согласно этому стилю после каждой открывающей скобки делается очередной отступ вправо, а после каждой закрывающей скобки на-чало отступа возвращается к прежнему уровню. Существуют также некоторые определенные инструкции, для которых предусматриваются дополнительные отступы (о них речь впереди).Ключевые слова C++
В стандарте C++ определено 63 ключевых слова. Они показаны в табл. 2.1. Эти ключевые слова (в сочетании с синтаксисом операторов и разделителей) образуют определение языка C++. В ранних версиях C++ определено ключевое слово overload, но теперь оно устарело.
Следует иметь в виду, что в C++ различается строчное и прописное написание букв. Ключевые слова не являются исключением, т.е. все они должны быть написаны строчными буквами. Например, слово RETURN не будет распознано в качестве ключевого слова return.
Идентификаторы в C++
В C++ идентификатор представляет собой имя, которое присваивается функции переменной или иному элементу, определенному пользователем. Идентификаторы могут состоять из одного или нескольких символов (значимыми должны быть первые символа). Имена переменных должны начинаться с буквы или символа подчеркивания Последующим символом может быть буква, цифра и символ подчеркивания. Символы подчеркивания можно использовать для улучшения читабельности имени переменной например first_name. В C++ прописные и строчные буквы воспринимаются как личные символы, т.е. myvar и MyVar — это разные имена. Вот несколько примеров допустимых идентификаторов.
В C++ нельзя использовать в качестве идентификаторов ключевые слова. Нельзя же использовать в качестве идентификаторов имена стандартных функций (например abs). Помните, что идентификатор не должен начинаться с цифры. Так, 12х— недопустимый идентификатор. Конечно, вы вольны называть переменные и другие программные элементы по своему усмотрению, но обычно идентификатор отражает н чение или смысловую характеристику элемента, которому он принадлежит.
Стандартная библиотека C++
В примерах программ, представленных в этой главе, использовалась функция abs(). По существу функция abs() не является частью языка C++, но ее "знает" каждый С++-компилятор. Эта функция, как и множество других, входит в состав стандартной библиотеки. В примерах этой книги мы подробно рассмотрим использование многих библиотечных функций C++. Стандартная библиотека C++ содержит множество встроенных функций, которые программисты могут использовать в своих программах. В C++ определен довольно большой набор функций, которые содержатся в стандартной библиотеке. Эти функции предназначены для выполнения часто встречающихся задач, включая операции ввода-вывода, математические вычисления и обработку строк. При использовании программистом библиотечной функции компилятор автоматически связывает объектный код этой функции с объектным кодом программы. Поскольку стандартная библиотека C++ довольно велика, в ней можно найти много полезных функций, которыми действительно часто пользуются программисты. Библиотечные функции можно применять подобно строительным блокам, из которых возводится здание. Чтобы не "изобретать велосипед", ознакомьтесь с документацией на библиотеку используемого вами компилятора. Если вы сами напишете функцию, которая будет "переходить" с вами от программы в программу, ее также можно поместить в библиотеку. Помимо библиотеки функций, каждый С++-компилятор также содержит библиотеку классов, которая является объектно-ориентированной библиотекой. Наконец, в C++ определена стандартная библиотека шаблонов (Standard Template Library— STL). Она предоставляет процедуры "многократного использования", которые можно настраивать в соответствии с конкретными требованиями. Но прежде чем применять библиотеку классов или STL, нам необходимо познакомиться с классами, объектами и понять, в чем состоит суть шаблона.Глава 3: Основные типы данных
Как вы узнали из главы 2, все переменные в C++ должны быть объявлены до их использования. Это необходимо для компилятора, которому нужно иметь информацию о типе данных, содержащихся в переменных. Только в этом случае компилятор сможет надлежащим образом скомпилировать инструкции, в которых используются переменные. В C++ определено семь основных типов данных: символьный, символьный двубайтовый, целочисленный, с плавающей точкой, с плавающей точкой двойной точности, логический (или булев) и "не имеющий значения". Для объявления переменных этих типов используются ключевые слова char, wchar_t, int, float, double, bool и void соответственно. Типичные размеры значений в битах и диапазоны представления для каждого из этих семи типов приведены в табл. 3.1. Помните, что размеры и диапазоны, используемые вашим компилятором, могут отличаться от приведенных здесь. Самое большое различие существует между 16- и 32-разрядными средами: для представления целочисленного значения в 16-разрядной среде используется, как правило, 16 бит, а в 32-разрядной — 32. Переменные типа char используются для хранения 8-разрядных ASCII-символов (например букв А, Б или В) либо любых других 8-разрядных значений. Чтобы задать символ, необходимо заключить его в одинарные кавычки. Тип wchar_t предназначен для хранения символов, входящих в состав больших символьных наборов. Вероятно, вам известно, что в некоторых естественных языках (например китайском) определено очень большое количество символов, для которых 8-разрядное представление (обеспечиваемое типом char) весьма недостаточно. Для решения проблем такого рода в язык C++ и был добавлен тип wchar_t, который вам пригодится, если вы планируете выходить со своими программами на международный рынок. Переменные типа int позволяют хранить целочисленные значения (не содержащие дробных компонентов). Переменные этого типа часто используются для управления циклами и в условных инструкциях. К переменным типа float и double обращаются либо для обработки чисел с дробной частью, либо при необходимости выполнения операций над очень большими или очень малыми числами. Типы float и double различаются значением наибольшего (и наименьшего) числа, которые можно хранить с помощью переменных этих типов. Как показано в табл. 3.1, тип double в C++ позволяет хранить число, приблизительно в десять раз превышающее значение типа float.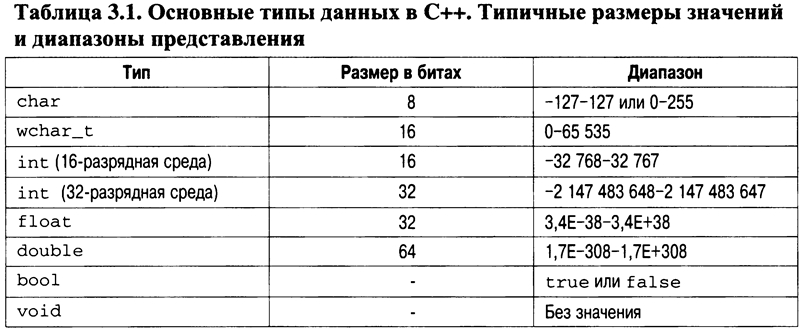
Тип bool предназначен для хранения булевых (т.е. ИСТИНА/ЛОЖЬ) значений. В C++ определены две булевы константы: true и false, являющиеся единственными значениями, которые могут иметь переменные типа bool. Как вы уже видели, тип void используется для объявления функции, которая не возвращает значения. Другие возможности использования типа void рассматриваются ниже в этой книге.
Объявление переменных
Общий формат инструкции объявления переменных выглядит так:тип список_переменных;
Здесь элемент тип означает допустимый в C++ тип данных, а элемент список_переменных может состоять из одного или нескольких имен (идентификаторов), разделенных запятыми. Вот несколько примеров объявлений переменных.
int i, j, k;
char ch, chr;
float f, balance;
double d;
В C++ имя переменной никак не связано с ее типом.
Согласно стандарту C++ первые 1024 символа любого имени (в том числе и имени переменной) являются значимыми. Это означает, что если два имени различаются хотя бы одним символом из первых 1024, компилятор будет рассматривать их как различные имена.
Переменные могут быть объявлены внутри функций, в определении параметров функций и вне всех функций. В зависимости от места объявления они называются локальными переменными, формальными параметрами и глобальными переменными соответственно. О важности этих трех типов переменных мы поговорим ниже в этой книге, а пока кратко рассмотрим каждый тип в отдельности.
Локальные переменные
Переменные, которые объявляются внутри функции, называются локальными. Их могут использовать только инструкции, относящиеся к телу функции. Локальные переменные неизвестны внешним функциям. Рассмотрим пример.#include <iostream>
using namespace std;
void func();
int main()
{
int x; // Локальная переменная для функции main().
х = 10;
func();
cout << "\n";
cout << x; // Выводится число 10.
return 0;
}
void func()
{
int x; // Локальная переменная для функции func().
x = -199;
cout << x; // Выводится число -199.
}
Локальная переменная известна только функции, в которой она определена.
В этой программе целочисленная переменная с именем х объявлена дважды: сначала в функции main(), а затем в функции func(). Но переменная х из функции main() не имеет никакого отношения к переменной х из функции func(). Другими словами, изменения, которым подвергается переменная х из функции func(), никак не отражаются на переменной х из функции main(). Поэтому приведенная выше программа выведет на экран числа -199 и 10.
В C++ локальные переменные создаются при вызове функции и разрушаются при выходе из нее. То же самое можно сказать и о памяти, выделяемой для локальных переменных: при вызове функции в нее записываются соответствующие значения, а при выходе из функции память освобождается. Это означает, что локальные переменные не поддерживают своих значений между вызовами функций. (Другими словами, значение локальной переменной теряется при каждом возврате из функции.)
В некоторых литературных источниках, посвященных C++, локальная переменная называется динамической или автоматической переменной. Но в этой книге мы будем придерживаться более распространенного термина локальная переменная.
Формальные параметры
Формальный параметр — это локальная переменная, которая получает значение аргумента, переданного функции. Как отмечалось в главе 2, если функция имеет аргументы, то они должны быть объявлены. Их объявление осуществляется с помощью формальных параметров. Как показано в следующем фрагменте, формальные параметры объявляются после имени функции, внутри круглых скобок.int funс1 (int first, int last, char ch)
{
.
.
.
}
Здесь функция funс1() имеет три параметра с именами first, last и ch. С помощью такого объявления мы сообщаем компилятору тип каждой из переменных, которые будут принимать значения, передаваемые функции. Несмотря на то что формальные параметры выполняют специальную задачу получения значений аргументов, передаваемых функции, их можно также использовать в теле функции как обычные локальные переменные. Например, мы можем присвоить им любые значения или использовать в ка-ких-нибудь (допустимых для C++) выражениях. Но, подобно любым другим локальным переменным, их значения теряются по завершении функции.
Глобальные переменные
Глобальные переменные известны всей программе. Чтобы придать переменной "всепрограммную" известность, ее необходимо сделать глобальной. В отличие от локальных, глобальные переменные хранят свои значения на протяжении всего времени жизни (времени существования) программы. Чтобы создать глобальную переменную, ее необходимо объявить вне всех функций. Доступ к глобальной переменной можно получить из любой функции. В следующей программе переменная count объявляется вне всех функций. Ее объявление предшествует функции main(). Но ее с таким же успехом можно разместить в другом месте, главное, чтобы она не принадлежала какой-нибудь функции. Помните: поскольку переменную необходимо объявить до ее использования, глобальные переменные лучше всего объявлять в начале программы.#include <iostream>
using namespace std;
void funс1();
void func2();
int count; // Это глобальная переменная.
int main()
{
int i; // Это локальная переменная.
for(i=0; i<10; i++){
count = i * 2;
funс1();
}
return 0;
}
void func1()
{
cout << "count: " << count; // Обращение к глобальной переменной.
cout << '\n'; // Вывод символа новой строки.
func2();
}
void func2()
{
int count; // Это локальная переменная.
for(count=0; count<3; count++) cout <<'.';
}
Несмотря на то что переменная count не объявляется ни в функции main(), ни в функции func1(), обе они могут ее использовать. Но в функции func2() объявляется локальная переменная count. Здесь при обращении к переменной count выполняется доступ к локальной, а не к глобальной переменной. Важно помнить, что, если глобальная и локальная переменные имеют одинаковые имена, все ссылки на "спорное" имя переменной внутри функции, в которой определена локальная переменная, относятся к локальной, а не к глобальной переменной.
Модификаторы типов
В C++ перед такими типами данных, как char, int и double, разрешается использовать модификаторы. Модификатор служит для изменения значения базового типа, чтобы он более точно соответствовал конкретной ситуации. Перечислим возможные модификаторы типов.signed
unsigned
long
short
Модификаторы signed, unsigned, long и short можно применять к целочисленным базовым типам. Кроме того, модификаторы signed и unsigned можно использовать с типом char, а модификатор long— с типом double. Все допустимые комбинации базовых типов и модификаторов для 16- и 32-разрядных сред приведены в табл. 3.2 и 3.3. В этих таблицах также указаны типичные размеры значений в битах и диапазоны представления для каждого типа. Безусловно, реальные диапазоны, поддерживаемые вашим компилятором, следует уточнить в соответствующей документации.
Изучая эти таблицы, обратите внимание на количество битов, выделяемых для хранения коротких, длинных и обычных целочисленных значений. Заметьте: в большинстве 16-разрядных сред размер (в битах) обычного целочисленного значения совпадает с размером короткого целого. Также отметьте, что в большинстве 32-разрядных сред размер (в битах) обычного целочисленного значения совпадает с размером длинного целого. "Собака зарыта" в С++-определении базовых типов. Согласно стандарту C++ размер длинного целого должен быть не меньше размера обычного целочисленного значения, а размер обычного целочисленного значения должен быть не меньше размера короткого целого. Размер обычного целочисленного значения должен зависеть от среды выполнения. Это значит, что в 16-разрядных средах для хранения значений типа int используется 16 бит, а в 32-разрядных — 32. При этом наименьший допустимый размер для целочисленных значений в любой среде должен составлять 16 бит. Поскольку стандарт C++ определяет только относительные требования к размеру целочисленных типов, нет гарантии, что один тип будет больше (по количеству битов), чем другой. Тем не менее размеры, указанные в обеих таблицах, справедливы для многих компиляторов.

Несмотря на разрешение, использование модификатора signed для целочисленных типов избыточно, поскольку объявление по умолчанию предполагает значение со знаком. Строго говоря, только конкретная реализация определяет, каким будет char-объявление: со знаком или без него. Но для большинства компиляторов объявление типа char подразумевает значение со знаком. Следовательно, в таких средах использование модификатора signed для char-объявления также избыточно. В этой книге предполагается, что char-значения имеют знак.


Различие между целочисленными значениями со знаком и без него заключается в интерпретации старшего разряда. Если задано целочисленное значение со знаком, С++-компилятор сгенерирует код с учетом того, что старший разряд значения используется в качестве флага знака. Если флаг знака равен 0, число считается положительным, а если он равен 1, — отрицательным. Отрицательные числа почти всегда представляются в дополнительном коде. Для получения дополнительного кода все разряды числа берутся в обратном коде, а затем полученный результат увеличивается на единицу. Целочисленные значения со знаком используются во многих алгоритмах, но максимальное число, которое можно представить со знаком, составляет только половину от максимального числа, которое можно представить без знака. Рассмотрим, например, максимально возможное 16-разрядное целое число (32 767): 0 1111111 11111111 Если бы старший разряд этого значения со знаком был установлен равным 1, то оно бы интерпретировалось как -1 (в дополнительном коде). Но если объявить его как unsigned int-значение, то после установки его старшего разряда в 1 мы получили бы число 65 535. Чтобы понять различие в С++-интерпретации целочисленных значений со знаком и без него, выполним следующую короткую программу.
#include <iostream>
using namespace std;
/* Эта программа демонстрирует различие между signed- и unsigned-значениями целочисленного типа.
*/
int main()
{
short int i; // короткое int-значение со знаком
short unsigned int j; // короткое int-значение без знака
j = 60000;
i = j;
cout << i << " " << j;
return 0;
}
При выполнении программа выведет два числа:
-5536 60000
Дело в том, что битовая комбинация, которая представляет число 60000 как короткое целочисленное значение без знака, интерпретируется в качестве короткого int-значения со знаком как число -5536.
В C++ предусмотрен сокращенный способ объявления unsigned-, short- и long-значений целочисленного типа. Это значит, что при объявлении int-значений достаточно использовать слова unsigned, short и long, не указывая тип int, т.е. тип int подразумевается. Например, следующие две инструкции объявляют целочисленные переменные без знака.
unsigned х;
unsigned int у;
Переменные типа char можно использовать не только для хранения ASCII-символов, но и для хранения числовых значений. Переменные типа char могут содержать "небольшие" целые числа в диапазоне -128--127 и поэтому их можно использовать вместо int-переменных, если вас устраивает такой диапазон представления чисел. Например, в следующей программе char-переменная используется для управления циклом, который выводит на экран алфавит английского языка.
// Эта программа выводит алфавит в обратном порядке.
#include <iostream>
using namespace std;
int main()
{
char letter;
for(letter='Z'; letter >= 'A'; letter--) cout << letter;
return 0;
}
Если цикл for вам покажется несколько странным, то учтите, что символ 'А' представляется в компьютере как число, а значения от 'Z' до 'А' являются последовательными и расположены в убывающем порядке.
Литералы
Литералы, называемые также константами, — это фиксированные значения, которые не могут быть изменены программой. Мы уже использовали литералы во всех предыдущих примерах программ. А теперь настало время изучить их более подробно. Константы могут иметь любой базовый тип данных. Способ представления каждой константы зависит от ее типа. Символьные константы заключаются в одинарные кавычки. Например, 'а' и '%' являются символьными литералами. Если необходимо присвоить символ переменной типа char, используйте инструкцию, подобную следующей:ch = 'Z';
Чтобы использовать двубайтовый символьный литерал (т.е. константу типа wchar_t), предварите нужный символ буквой L. Например, так.
wchar_t wc;
wc = L'A';
Здесь переменной wc присваивается двубайтовая символьная константа, эквивалентная букве А.
Целочисленные константы задаются как числа без дробной части. Например, 10 и -100 — целочисленные литералы. Вещественные литералы должны содержать десятичную точку, за которой следует дробная часть числа, например 11.123. Для вещественных констант можно также использовать экспоненциальное представление чисел.
Существует два основных вещественных типа: float и double. Кроме того, существует несколько модификаций базовых типов, которые образуются с помощью модификаторов типов. Интересно, а как же компилятор определяет тип литерала? Например, число 123.23 имеет тип float или double? Ответ на этот вопрос состоит из двух частей. Во-первых, С++-компилятор автоматически делает определенные предположения насчет литералов. Во-вторых, при желании программист может явно указать тип литерала.
По умолчанию компилятор связывает целочисленный литерал с совместимым и одновременно наименьшим по занимаемой памяти тип данных, начиная с типа int. Следовательно, для 16-разрядных сред число 10 будет связано с типом int, а 103 000— с типом long int.
Единственным исключением из правила "наименьшего типа" являются вещественные (с плавающей точкой) константы, которым по умолчанию присваивается тип double. Во многих случаях такие стандарты работы компилятора вполне приемлемы. Однако у программиста есть возможность точно определить нужный тип.
Чтобы задать точный тип числовой константы, используйте соответствующий суффикс. Для вещественных типов действуют следующие суффиксы: если вещественное число завершить буквой F, оно будет обрабатываться с использованием типа float, а если буквой L, подразумевается тип long double. Для целочисленных типов суффикс U означает использование модификатора типа unsigned, а суффикс L— long. (Для задания модификатора unsigned long необходимо указать оба суффикса U и L.) Ниже приведены некоторые примеры.

Шестнадцатеричные и восьмеричные литералы
Иногда удобно вместо десятичной системы счисления использовать восьмеричную или шестнадцатеричную. В восьмеричной системе основанием служит число 8, а для выражения всех чисел используются цифры от 0 до 7. В восьмеричной системе число 10 имеет то же значение, что число 8 в десятичной. Система счисления по основанию 16 называется шестнадцатеричной и использует цифры от 0 до 9 плюс буквы от А до F, означающие шестнадцатеричные "цифры" 10, 11, 12, 13, 14 и 15. Например, шестнадцатеричное число 10 равно числу 16 в десятичной системе. Поскольку эти две системы счисления (шестнадцатеричная и восьмеричная) используются в программах довольно часто, в языке C++ разрешено при желании задавать целочисленные литералы не в десятичной, а в шестнадцатеричной или восьмеричной системе. Шестнадцатеричный литерал должен начинаться с префикса 0x (нуль и буква х) или 0Х, а восьмеричный — с нуля. Приведем два примера.int hex = OxFF; // 255 в десятичной системе
int oct = 011; // 9 в десятичной системе
Строковые литералы
Язык C++ поддерживает еще один встроенный тип литерала, именуемый строковым. Строка— это набор символов, заключенных в двойные кавычки, например "это тест". Вы уже видели примеры строк в некоторых cout-инструкциях, с помощью которых мы выводили текст на экран. При этом обратите внимание вот на что. Хотя C++ позволяет определять строковые литералы, он не имеет встроенного строкового типа данных. Строки в C++, как будет показано ниже в этой книге, поддерживаются в виде символьных массивов. (Кроме того, стандарт C++ поддерживает строковый тип с помощью библиотечного класса string, который также описан ниже в этой книге.) Осторожно! Не следует путать строки с символами. Символьный литерал заключается в одинарные кавычки, например 'а'. Однако "а" — это уже строка, содержащая только одну букву.Управляющие символьные последовательности
С выводом большинства печатаемых символов прекрасно справляются символьные константы, заключенные в одинарные кавычки, но есть такие "экземпляры" (например, символ возврата каретки), которые невозможно ввести в исходный текст программы с клавиатуры. Некоторые символы (например, одинарные и двойные кавычки) в C++ имеют специальное назначение, поэтому иногда их нельзя ввести напрямую. По этой причине в языке C++ разрешено использовать ряд специальных символьных последовательностей (включающих символ "обратная косая черта"), которые также называются управляющими последовательностями. Их список приведен в табл. 3.4. Использование управляющих последовательностей демонстрируется на примере следующей программы. При ее выполнении будут выведены символы перехода на новую строку, обратной косой черты и возврата на одну позицию.#include <iostream>
using namespace std;
int main()
{
cout<<"\n\\\b";
return 0;
}

Инициализация переменных
При объявлении переменной ей можно присвоить некоторое значение, т.е. инициализировать ее, записав после ее имени знак равенства и начальное значение. Общий формат инициализации имеет следующий вид:тип имя_переменной = значение;
Вот несколько примеров.
char ch = 'а';
int first = 0;
float balance = 123.23F;
Несмотря на то что переменные часто инициализируются константами, C++ позволяет инициализировать переменные динамически, т.е. с помощью любого выражения, действительного на момент инициализации. Как будет показано ниже, инициализация играет важную роль при работе с объектами.
Глобальные переменные инициализируются только в начале программы. Локальные переменные инициализируются при каждом входе в функцию, в которой они объявлены. Все глобальные переменные инициализируются нулевыми значениями, если не указаны никакие иные инициализаторы. Неинициализированные локальные переменные будут иметь неизвестные значения до первой инструкции присваивания, в которой они используются.
Рассмотрим простой пример инициализации переменных. В следующей программе используется функция total(), которая предназначена для вычисления суммы всех последовательных чисел, начиная с единицы и заканчивая числом, переданным ей в качестве аргумента. Например, сумма ряда чисел, ограниченного числом 3, равна 1 + 2 + 3 = 6. В процессе вычисления итоговой суммы функция total() отображает промежуточные результаты. Обратите внимание на использование переменной sum в функции total().
// Пример использования инициализации переменных.
#include <iostream>
using namespace std;
void total(int x);
int main()
{
cout << "Вычисление суммы чисел от 1 до 5.\n";
total(5);
cout << "\n Вычисление суммы чисел от 1 до 6.\n";
total(6);
return 0;
}
void total(int x)
{
int sum=0; // Инициализируем переменную sum.
int i, count;
for(i=1; i<=x; i++) {
sum = sum + i;
for(count=0; count<10; count++) cout << '.';
cout << "Промежуточная сумма равна " << sum << '\n';
}
}
Результаты выполнения этой программы таковы.
Вычисление суммы чисел от 1 до 5.
..........Промежуточная сумма равна 1
..........Промежуточная сумма равна 3
..........Промежуточная сумма равна 6
..........Промежуточная сумма равна 10
..........Промежуточная сумма равна 15
Вычисление суммы чисел от 1 до 6.
..........Промежуточная сумма равна 1
..........Промежуточная сумма равна 3
..........Промежуточная сумма равна 6
..........Промежуточная сумма равна 10
..........Промежуточная сумма равна 15
..........Промежуточная сумма равна 21
Как видно по результатам, при каждом вызове функции total() переменная sum инициализируется нулем.
Операторы
В C++ определен широкий набор встроенных операторов, которые дают в руки программисту мощные рычаги управления при создании и вычислении разнообразнейших выражений. Оператор (operator) — это символ, который указывает компилятору на выполнение конкретных математических действий или логических манипуляций. В C++ имеется четыре общих класса операторов: арифметические, поразрядные, логические и операторы отношений. Помимо них определены другие операторы специального назначения. В этой главе рассматриваются арифметические, логические и операторы отношений.Арифметические операторы
В табл. 3.5 перечислены арифметические операторы, разрешенные для применения в C++. Действие операторов +, -, * и / совпадает с действием аналогичных операторов в любом другом языке программирования (да и в алгебре, если уж на то пошло). Их можно применять к данным любого встроенного числового типа. После применения оператора деления (/) к целому числу остаток будет отброшен. Например, результат целочисленного деления 10/3 будет равен 3.
Остаток от деления можно получить с помощью оператора деления по модулю (%). Этот оператор работает практически так же, как в других языках программирования: возвращает остаток от деления нацело. Например, 10%3 равно 1. Это означает, что в C++ оператор "%" нельзя применять к типам с плавающей точкой (float или double). Деление по модулю применимо только к целочисленным типам. Использование этого оператора демонстрируется в следующей программе.
#include <iostream>
using namespace std;
int main()
{
int x, y;
x = 10;
y = 3;
cout << х/у; // Будет отображено число 3.
cout << "\n";
cout << х%у; /* Будет отображено число 1, т.е. остаток от деления нацело. */
cout << "\n";
х = 1;
y = 2;
cout << х/у << " " << х%у; // Будут выведены числа 0 и 1.
return 0;
}
В последней строке результатов выполнения этой программы действительно будут выведены числа 0 и 1, поскольку при целочисленном делении 1/2 получим 0 с остатком 1, т.е. выражение 1%2 дает значение 1.
Унарный минус, по сути, представляет собой умножение значения своего единственного операнда на -1. Другими словами, любое числовое значение, которому предшествует знак меняет свой знак на противоположный.
Инкремент и декремент
В C++ есть два оператора, которых нет в некоторых других языках программирования. Это операторы инкремента (++) и декремента (--). Они упоминались в главе 2, когда речь шла о цикле for. Оператор инкремента выполняет сложение операнда с числом 1, а оператор декремента вычитает 1 из своего операнда. Это значит, что инструкциях = х + 1;
аналогична такой инструкции:
++х;
А инструкция
х = х - 1;
аналогична такой инструкции:
--x;
Операторы инкремента и декремента могут стоять как перед своим операндом (префиксная форма), так и после него (постфиксная форма). Например, инструкцию
х = х + 1;
можно переписать в виде префиксной формы
++х; // Префиксная форма оператора инкремента.
или в виде постфиксной формы:
х++; // Постфиксная форма оператора инкремента.
В предыдущем примере не имело значения, в какой форме был применен оператор инкремента: префиксной или постфиксной. Но если оператор инкремента или декремента используется как часть большего выражения, то форма его применения очень важна. Если такой оператор применен в префиксной форме, то C++ сначала выполнит эту операцию, чтобы операнд получил новое значение, которое затем будет использовано остальной частью выражения. Если же оператор применен в постфиксной форме, то C++ использует в выражении его старое значение, а затем выполнит операцию, в результате которой операнд обретет новое значение. Рассмотрим следующий фрагмент кода:
х = 10;
у = ++x; ... Все права на текст принадлежат автору: Herbert Schildt.
Это короткий фрагмент для ознакомления с книгой.