C# для профессионалов
Том II
Глава 13
XML
XML играет очень большую роль в платформе .NET. Платформа не только позволяет использовать XML в приложениях, но сама применяет XML для таких вещей, как конфигурационные файлы и документация исходного кода. Для XML платформа .NET содержит пространство имен
System.Xml. Это пространство имен загружается вместе с классами, задействованными при обработке XML.
В этой главе говорится о том, как использовать реализацию DOM, и что предлагает .NET в качестве замены SAX. Будет показана совместная работа XML и ADO.NET и их преобразования. Мы узнаем так же, как можно сериализовать объекты в документ XML и создать объект из документа XML (десериализовать). Кроме того увидим, как включать XML в приложения C#. Следующие классы будут рассмотрены более подробно:
□
XmlReader и
XmlTextReader
□
XmlWriter и
XmlTextWriter
□
XmlDocument и DOM
□
XPath и
XslTransform
□
ADO.NET и
XmlDataDocument
□
XmlSerialization
Начнем эту главу с текущего состояния стандартов XML.
Стандарты W3C
Консорциум WWW (W3C) разработал множество стандартов, придающих XML мощь и потенциал. Без этих стандартов XML не смог бы оказать такого большого влияния на мир разработки. В этой книге не будут подробно рассматриваться тонкости XML. Для этого необходимо использовать другие источники. Среди книг Wrox, переведенных издательством "Лори", можно порекомендовать "Введение в XML" (2001 г., 656 стр.), "XML для профессионалов" (2001 г., 896 стр.) и "The XML Handbook" (ISBN 0-13-055068). Конечно, web-сайт W3C является ценным источником информации о XML (www.w3.org). В мае 2001 г. платформа .NET поддерживала следующие стандарты:
□ XML 1.0 — www.w3.org/TR/1998/REC-XML-19980210 — включая поддержку DTD (
XmlTextReader).
□ Пространства имен XML — www.w3.org/TR/REC-xml-names — уровень потока и DOM.
□ Схемы XML — www.w3.org/TR/xmlschema-1 — поддерживается отображение схем и сериализация, но пока еще не поддерживается проверка.
□ Выражения XPath — www.w3.org/TR/xpath
□ Преобразования XSL/T — www.w3.org/TR/xslt
□ Ядро DOM Level 2 — www.w3.org/TR/DOM-Level-2
□ Soap 1.1 — msdn.microsoft.com/xml/general/soapspec.asp
Уровень поддержки стандартов будет меняться по мере развития платформы и по мере того, как W3C продолжает обновлять рекомендованные стандарты. В связи с этим необходимо всегда оставаться на современном уровне стандартов и уровне поддержки, который обеспечивает Microsoft.
Пространство имен System.Xml
Рассмотрим (без определенного порядка) некоторые классы пространства имен System.Xml.
| Имя класса |
Описание |
XmlReader |
Абстрактный. Средство чтения, которое предоставляет быстрый, некэшированный доступ к данным XML. XmlReader читает только вперед, аналогично синтаксическому анализатору SAX. |
XmlWriter |
Абстрактный. Средство записи, которое предоставляет быструю, некэшированную запись данных XML в поток или файл. |
XmlTextReader |
Реализует XmlReader. Предоставляет быстрый потоковый доступ для чтения с режимом только вперед к данным XML. Разрешает (допускает) использование данных в одном представлении. |
XmlTextWriter |
Реализует XmlWriter. Быстрая генерация потоков записи XML с режимом только вперед. |
XmlNode |
Абстрактный. Класс, который представляет единичный узел в документе XML. Базовый класс для нескольких классов в пространстве имен XML. |
XmlDocument |
Реализует XmlNode. Объектная модель документов W3C (DOM, Document Object Model). Задает в памяти представление документа XML в виде дерева, разрешая перемещение и редактирование. |
XmlDataDocument |
Реализует XmlDocument. То есть документ, который можно загрузить из данных XML или из реляционных данных объекта DataSet из ADO.NET. |
XmlResolver |
Абстрактный. Разрешает внешние ресурсы на основе XML, такие как DTD и схемные ссылки. Используется также для обработки элементов <xsl:include> и <xsl:import>. |
XmlUrlResolver |
Реализует XmlResolver. Разрешает внешние ресурсы с помощью URI (унифицированный идентификатор ресурса). |
XML является также частью пространства имен
System.Data в классе
DataSet.
| Имя класса |
Описание |
ReadXml |
Считывает данные XML и схему в DataSet. |
ReadXmlSchema |
Считывает схему XML в DataSet. |
WriteXml |
Переписывает XML и схему из DataSet в документ XML. |
WriteXmlSchema |
Переписывает схему из DataSet в документ XML. |
Необходимо отметить, что эта книга посвящена языку C#, поэтому все примеры будут написаны на C#. Однако пространство имен XML доступно в любом языке, который является частью семейства .NET. Это означает, что все приведенные примеры могли быть также написаны на языках VB.NET, Управляемый C++ и т.д.
XML 3.0 (MSXML3.DLL) в C#
Как быть, если имеется большой объем кода, разработанного с помощью синтаксического анализатора компании Microsoft (в настоящее время XML 3.0)? Придется ли его выбросить и начать все сначала? А что если вам удобно использовать объектную модель XML 3.0 DOM? Нужно ли немедленно переключаться на .NET?
Ответом будет — нет. XML 3.0 может использоваться непосредственно в приложениях. Если добавить ссылку на msxml3.DLL в свое решение, то можно будет начать писать некоторый код.
Следующие несколько примеров будут использовать файл books.xml в качестве источника данных. Его можно загрузить с web-сайта издательства Wrox, он также включен в несколько примеров .NET SDK. Файл books.xml является каталогом книг воображаемого книжного склада. Он содержит такую информацию, как жанр, имя автора, цена и номер ISBN. Все примеры кода в этой главе также доступны на web-сайте издательства Wrox: www.wrox.com. Чтобы выполнить эти примеры, файлы данных XML должны находиться в структуре путей, которая выглядит примерно следующим образом:
/XMLChapter/Sample1
/XMLChapter/Sample2
/XMLChapter/Sample3
и т. д. Файлы XML должны находиться в подкаталоге XMLChapter, а код для примеров должен быть в подкаталогах Sample1, Sample2 и т.д. Можно называть каталоги как угодно, но их относительное положение важно. Можно также изменять примеры, чтобы указать желаемое направление. В коде примеров будут сделаны указания, какие строки изменить.
Файл books.xml выглядит следующим образом:
<?xml version='1.0'?>
<!-- Этот файл представляет фрагмент базы данных учета запасов книжного склада -->
<bookstore>
<book genre="autobiography" publicationdate="1981" ISBN="1-861003-11-0">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<book genre="novel" publicationdate="1967" ISBN="0-201-63361-2">
<title>The Confidence Man</title>
<author>
<first-name>Herman</first-name>
<last-name>Melville</last-name>
</author>
<price>11.99</price>
</book>
<book genre="philosophy" publicationdate="1991" ISBN="1-861001-57-6">
<title>The Gorgias</title>
<author>
<name>Plato</name>
</author>
<price>9.99</price>
</book>
</bookstore>
Рассмотрим пример кода, использующего MSXML 3.0 для загрузки окна списка с номерами ISBN из
books.xml. Ниже записан код, который можно найти в папке
SampleBase1 архива, загружаемого с web-сайта издательства Wrox. Можно скопировать его в Visual Studio IDE или создать новую форму Windows Form с самого начала. Эта форма содержит элементы управления
listbox и
button. Оба элемента используют имена по умолчанию
listBox1 и
button1:
namespace SampleBase {
using System;
using System.Drawing;
using System.Collections;
using System.ComponentModel;
using System.Windows.Forms;
using System.Data;
Затем включается пространство имен для ссылки на
msxml3.dll. Помните, что ссылку на эту библиотеку необходимо включать в проект (ее можно найти на вкладке COM диалогового окна Add Reference).
using MSXML2;
/// <summary>
/// Краткое описание Form1.
/// </summary>
public class Form1 : System.Windows.Forms.Form {
private System.Windows.Forms.ListBox listBox1;
private System.Windows.Forms.Button button1;
/// <summary>
/// Необходимая для Designer переменная.
/// </summary>
private System.ComponentModel.Container components;
Затем объявляется документ DOM на уровне модуля:
private DOMDocument30 doc;
public Form1() {
//
// Требуется для поддержки Windows Form Designer
//
InitializeComponent();
//
// TODO: Добавьте любой код конструктора после вызова
// InitializeComponent
//
}
/// <summary>
/// Очистить все использованные ресурсы.
/// </summary>
public override void Disposed {
base.Dispose();
if (components != null) components.Dispose();
}
#region Windows Form Designer создает код
/// <summary>
/// Необходимый для поддержки Designer метод — не изменяйте
/// содержимое этого метода редактором кода.
/// </summary>
private void InitializeComponent() {
this.listBox1 = new System.Windows.Forms.ListBox();
this.button1 = new System.Windows.Forms.Button();
this.listBox1.Anchor = ((System.Windows.Forms.AnchorStyles.Top |
System.Windows.Forms.AnchorStyles.Left) |
System.Windows.Forms.AnchorStyles.Right);
this.listBox1.Size = new System.Drawing.Size(336, 238);
this.listBox1.TabIndex = 0;
this.listBox1.SelectedIndexChanged += new System.EventHandler(this.listBox1_SelectedIndexChanged);
this.button1.Anchor = System.Windows.Forms.AnchorStyles.Bottom;
this.button1.Location = new System.Drawing.Point(136, 264);
this.button1.TabIndex = 1;
this.button1.Text = "button1";
this.button1.Click += new System.EventHandler(this.button1_Click);
this.AutoScaleBaseSize = new System.Drawing.Size(5, 13);
this.ClientSize = new System.Drawing.Size(339, 320);
this.Controls.AddRange(new System.Windows.Forms.Control[]{this.button1, this.listBox1});
this.Text = "Form1";
}
#endregion
/// <summary>
/// Главная точка входа для приложения.
/// </summary>
[STAThread]
static void Main() {
Application.Run(new Form1());
}
Мы хотим взять номер ISBN из
listbox и, используя простой поиск
XPath, найти узел книги, который ему соответствует, и вывести текст узла (заглавие книги и цену) в
MessageBox. Язык пути доступа XML (XPath) является нотацией XML, которая может использоваться для запроса и фильтрации текста в документе XML. Рассмотрим XPath в .NET позже в этой главе. Вот код обработчика событий для выбора записи в окне списка:
protected void listBox1_SelectedIndexChanged (object sender, System.EventArgs e){
string srch=listBox1.SelectedItem.ToString();
IXMLDOMNode nd=doc.selectSingleNode("bookstore/book[@ISBN='" + srch + "']");
MessageBox.Show(nd.text);
}
Теперь мы имеем обработчик события нажатия кнопки. Сначала мы загружаем файл
books.xml — обратите внимание, что если файл выполняется не в папке
bin/debug или
bin/release, необходимо исправить соответствующим образом путь доступа:
protected void button1_Click(object sender, System.EventArgs e) {
doc=new DOMDocument30();
doc.load("..\\..\\..\\books.xml")
Следующие строки объявляют, что узлы являются
nodeList узлов книг. В данном случае имеется три узла:
IXMLDOMNodeList nodes;
nodes = doc.selectNodes("bookstore/book");
IXMLDOMNode node=nodes.nextNode();
Мы просматриваем узлы в цикле и добавляем текстовое значение атрибута ISBN в
listBox1:
while(node!=null) {
listBox1.Items.Add(node.attributes.getNamedItem("ISBN").text);
node=nodes.nextNode();
}
}
}
}
Вот как выглядит пример во время выполнения:

Это изображение появляется после того, как была нажата кнопка button1 и загрузился listBox1 с номерами ISBN книг. После выбора номера ISBN будет выведено следующее:

System.Xml
Пространство имен
System.Xml является мощным и относительно простым для использования, но оно отличается от модели MSXML 3.0. Если вы знакомы с MSXML 3.0, то применяйте его, пока не освоитесь с пространством имен
System.Xml. Пространство имен
System.Xml предлагает большую гибкость и легче расширяется.
Этот файл XML будет использоваться в примерах этой главы. Код, который только что был рассмотрен, лежит в основе нескольких примеров. В большинстве других будет показан только код, имеющий отношение к делу, и не будет повторяться то, что уже было показано.
Чтение и запись XML
Теперь посмотрим, что позволяет делать платформа .NET. Если раньше вы работали с SAX, то
XmlReader и
XmlWriter вам будут знакомы. Классы на основе
XmlReader предоставляют быстрый курсор только для чтения вперед, который создает поток данных XML для обработки. Так как это потоковая модель, то требования к памяти не очень большие. Однако в ней отсутствует навигационная гибкость и средства чтения/записи, присущие модели DOM. Классы на основе
XmlWriter будут создавать документ XML, который соответствует рекомендациям по пространствам имен XML 1.0 консорциума W3C.
XmlReader и
XmlWriter являются абстрактными классами. Рисунок ниже показывает, какие классы являются производными от
XmlReader и
XmlWriter:

XmlTextReader и
XmlTextWriter работают либо с объектами на основе потока, либо с объектами на основе
TextReader или
TextWriter.
XmlNodeReader использует
XmlNode вместо потока в качестве своего источника.
XmlValidatingReader добавляет DTD и проверку схем и поэтому предлагает проверку данных. Мы рассмотрим это подробнее позже в этой главе.
XmlTextReader
XmlTextReader похож на SAX. Одно из различий заключается в том, что SAX является моделью типа рассылки (push), т.е. посылает данные приложению и разработчик должен быть готов принять их, a
XmlTextReader применяет модель запроса (pull), где данные посылаются приложению, которое их запрашивает. Это предоставляет более простую и интуитивно понятную модель для программирования. Другое преимущество состоит в том, что модель запроса может быть избирательной в отношении данных, посылаемых приложению. Если нужны не все данные, то их не нужно обрабатывать. В модели рассылки все данные XML должны быть обработаны приложением, нужны они ему или нет.
Возьмем простой пример считывания данных XML, и затем более внимательно рассмотрим класс
XmlTextReader. Код можно найти в папке
XmlReaderSample1. Можно заменить метод
button1_Click в предыдущем примере на следующий код. Эту версию данного кода можно найти в папке
SampleBase2 загруженного архива кода. Не забудьте изменить:
using MSXML2;
на
using System.Xml;
Мы должны это сделать, поскольку используем теперь не MSXML 3.0, а пространство имен
System.Xml. Нужно также удалить метод
listBox1_SelectedIndexChanged, так как он включает в себя некоторые неподдерживаемые методы и строку:
private DOMDocument30 doc;
protected void button1_Click(object sender, System.EventArgs e) {
// Измените этот путь доступа, чтобы найти books.xml
string fileName = "..\\..\\..\\books.xml";
// Создать новый объект TextReader
XmlTextReader tr = new XmlTextReader(fileName);
// Прочитать узел за раз
while(tr.Read()) {
if (tr.NodeType == XmlNodeType.Text) listBox1.Items.Add(tr.Value);
}
}
Это
XmlTextReader в простейшей форме. Сначала создается строковый объект
fileName с именем файла XML. Затем создается новый объект
XmlTextReader, передавая в качестве параметра строку
fileName.XmlTextReader в настоящее время имеет 13 различных перегружаемых конструкторов, которые получают различные комбинации строк (имен файлов и URL), потоков и таблиц имен. После инициализации объекта
XmlTextReader ни один узел не выбран. Это единственный момент, когда узел не является текущим. Когда мы начинаем цикл
tr.Read, первая операция чтения
Read переместит нас в первый узел документа. Обычно это бывает узел Declaration XML. В этом примере при переходе к каждому узлу
tr.NodeType сравнивается с перечислением
XmlNodeType, и когда встречается текстовый узел, значение текста добавляется в
listbox. Вот экран после того, как было загружено окно списка:

Существует несколько способов перемещения по документу. Как мы только что видели,
Read перемещает нас к следующему узлу. Затем можно проверить, имеет ли узел значение (
HasValue) или, как мы скоро увидим, имеет ли узел атрибуты (
HasAttributes). Существует метод
ReadStartElement, который проверяет, является ли текущий узел начальным элементом, и затем перемешает текущую позицию к следующему узлу. Если текущая позиция не является начальным элементом, то порождается исключение
XmlException. Этот метод совпадает с вызовом метода
IsStartElement, за которым следует метод
Read.
Методы
ReadString и
ReadCharts считывают текстовые данные из элемента.
ReadString возвращает строковый объект, содержащий данные, в то время как
ReadCharts считывает данные в заданный массив символов.
Метод
ReadElementString аналогичен методу
ReadString, за исключением того, что при желании можно передать в него имена элемента. Если следующий узел содержимого не является начальным тегом или, если параметр
Name не совпадает с именем (
Name) текущего узла, то порождается исключение. Вот пример того, как это может использоваться (код можно найти в папке
XmlReaderSample2):
protected void button1_Click(object sender, System.EventArgs e) {
// Использовать файловый поток для получения данных
FileStream fs = new FileStream("..\\..\\..\\books.xml", FileMode.Open);
XmlTextReader tr = new XmlTextReader(fs);
while(!tr.EOF) {
// если встретился тип элемента, проверить и загрузить его в окно списка
if (tr.MoveToContent()==XmlNodeType.Element && tr.Name=="title") {
listBox1.Items.Add(tr.ReadElementString());
} else
//иначе двигаться дальше
tr.Read();
}
}
В цикле
while используется метод
MoveToContent для поиска каждого узла типа
XmlNodeType.Element с именем
title. Если это условие не выполняется, то предложение
else вызывает метод
Read для перехода к следующему узлу. Если будет найден узел, соответствующий критерию, то результат работы метода
ReadElementString добавляется в
listbox. Таким образом мы получим заглавия книг в
listbox. Отметим, что после успешного применения
ReadElementString метод
Read не вызывается. Это связано с тем, что метод
ReadElementString обрабатывает весь
Element и перемещается к следующему узлу.
Если удалить
&& tr.Name=="title" из предложения
if, то придется отслеживать исключение
XmlException, когда оно будет порождаться. При просмотре файла данных можно заметить, что первым элементом, который найдет метод MoveToContent, является элемент
<bookstore>. Как элемент он будет проходить проверку в операторе
if. Но так как он не содержит простой текстовый тип, он вынуждает метод
ReadElementString порождать исключение
XmlException. Одним из способов обхода этой проблемы является размещение вызова
ReadElementString в своей собственной функции. Назовем ее
LoadList.
XmlTextReader передается в нее в качестве параметра. Теперь, если вызов
ReadElementString отказывает внутри этой функции, мы можем иметь дело с ошибкой и вернуться назад в вызывающую функцию. Вот как выглядит пример с этими изменениями (код можно найти в папке
XmlReaderSample3):
protected void button1_Click(object sender, System.EventArgs e) {
// использовать файловый поток для получения данных
FileStream fs = new FileStream("..\\..\\..\\books.xml", FileMode.Open);
XmlTextReader tr = new XmlTextReader(fs);
while(!tr.EOF) {
// если встретился тип элемента, проверить и загрузить его в окно списка
if (tr.MoveToContent() == XmlNodeType.Element) {
LoadList(tr);
} else
// иначе двигаться дальше
tr.Read();
}
}
private void LoadList(XmlReader reader) {
try {
listBox1.Items.Add(reader.ReadElementString());
}
//если инициировано исключение XmlException, игнорировать его.
catch(XmlException er){}
}
Вот что должно появиться, когда код будет выполнен:
Это тот же результат, который был раньше. Мы видим, что существует более одного способа достичь одной и той же цели. При этом становится очевидной гибкость пространства имен
System.Xml.
По мере чтения узлов можно заметить отсутствие каких-либо атрибутов. Это связано с тем, что атрибуты не считаются частью структуры документа. При нахождении в узле элемента мы можем проверить наличие атрибутов и получить значения атрибутов. Метод
HasAttributes возвращает
true, если существуют какие-либо атрибуты, иначе возвращается
false. Свойство
AttributeCount сообщит, сколько имеется атрибутов. Метод
GetAttribute получает атрибут по имени или по индексу. Если желательно просмотреть все атрибуты по очереди, можно использовать методы
MoveToFirstAttribute (перейти к первому атрибуту) и
MoveToNextAttribute (перейти к следующему атрибуту). Вот пример просмотра атрибутов из
XmlReaderSample4:
protected void button1_Click(object sender, System.EventArgs e) {
// задаем путь доступа в соответствии со структурой путей доступа
// к данным
string fileName = "..\\..\\..\\books.xml";
// Создать новый объект TextReader
XmlTextReader tr = new XmlTextReader(filename);
// Прочитать узел за раз
while (tr.Read()) {
// проверить, что это элемент NodeType
if (tr.NodeType = XmlNodeType.Element) {
// если это — элемент, то посмотрим атрибуты
for(int i=0; i<tr.AttributeCount; i++) {
listBox1.Items.Add(tr.GetAttribute(i));
}
}
}
}
На этот раз мы ищем узлы элементов. Когда такой узел найден, в цикле просматриваются все атрибуты и с помощью метода
GetAttribute значение атрибута загружается в
listbox.
Проверка
Если нужно проверить документ XML, используйте класс
XmlValidatingReader. Он обладает всей функциональностью класса
XmlTextReader (оба реализуют
XmlReader, но
XmlValidatingReader добавляет свойство
ValidationType, свойство
Schemes и свойство
SchemaType). Свойство
ValidationType задается как тип проверки, которую желательно выполнить. Допустимые значения этого свойства следующие:
| Значение свойства |
Описание |
Auto |
Если в <!DOCTYPE...> объявлен DTD, он и будет загружаться и обрабатываться. Атрибуты по умолчанию и общие сущности, определенные в DTD, станут доступными. Если найден атрибут XSD schemalocation, то загружается и обрабатывается XSD, при этом все атрибуты по умолчанию, определенные в схеме, будут возвращены. Если найдено пространство имен с префиксом MSXML x-schema:, загрузится и обработается схема XDR, все атрибуты, определенные по умолчанию, возвратятся. |
DTD |
Проверка согласно правилам DTD. |
Schema |
Проверка согласно правилам XSD. |
XDR |
Проверка согласно правилам XDR. |
None |
Проверка не выполняется. |
Если свойство задано, то должен быть назначен обработчик событий
ValidationEventHandler. Событие инициируется, когда случается ошибка проверки. На ошибку можно отреагировать любым подходящим образом. Рассмотрим пример. Добавим пространство имен схемы XDR (XML Data Reduced — приведенные данные XML) к файлу
books.xml и назовем этот файл
booksVal.xml. Теперь он выглядит так:
<?xml version='1.0'?>
<!-- Этот файл представляет фрагмент базы данных учета запасов книжного склада -->
<bookstore xmlns="x-schema:books.xdr">
<book genre="autobiography" publicationdate="1981" ISBN="1-861003-11-0">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<book genre="novel" publicationdate="1967" ISBN="0-201-63361-2">
<title>The Confidence Man</title>
<author>
<first-name>Herman</first-name>
<last-name>Melville</last-name>
</author>
<price>11.99</price>
</book>
<book genre="philosophy" publicationdate="1991" ISBN="1-861001-57-6">
<title>The Gorgias</title>
<author>
<name>Plato</name>
</author>
<price>9.99</price>
</book>
</bookstore>
Отметим, что элемент
bookstore имеет теперь атрибут
xmlns="x-schema:books.xdr". Это будет указывать на следующую схему XDR:
<?xml version="1.0"?>
<Schema xmlns="urn:schemas-microsoft-com:xml-data" xmlns:dt="urn:schemas-microsoft-com:datatypes">
<ElementType name="first-name" content="textOnly"/>
<ElementType name="last-name" content="textOnly"/>
<ElementType name="name" content="textOnly"/>
<ElementType name="price" content="textOnly" dt:type="fixed.14.4"/>
<ElementType name="author" content="eltOnly" order="one">
<group order="seq">
<element type="name"/>
</group>
<group order="seq">
<element type="first-name"/>
<element type="last-name"/>
</group>
</ElementType>
<ElementType name="title" content="textOnlу" />
<AttributeType name="genre" dt:type="string"/>
<ElementType name="book" content="eltOnly">
<attribute type="genre" required="yes"/>
<element type="title"/>
<element type="author"/>
<element type="price"/>
</ЕlementType>
<ElementType name="bookstore" content="eltOnly">
<element type="book"/>
</ElementType>
</Schema>
Отметим, что имеются два атрибута в файле XML, которые не определены в схеме. Если посмотреть внимательно, то можно увидеть что в схеме нет атрибутов
publication-date и ISBN из элемента
book. Мы сделали это, чтобы показать, что проверка действительно выполняется. Можно использовать для подтверждения этого следующий код. Необходимо будет добавить в класс
using System.Xml.Schema. Весь код доступен в
XMLReaderSample5:
protected void button1_Click (object sender, System.EventArgs e) {
//измените это в соответствии с используемой структурой путей доступа.
string filename = "..\\..\\..\\booksVal.xml";
XmlTextReader tr = new XmlTextReader(filename);
XmlValidatingReader trv=new XmlValidatingReader(tr);
// Задать тип проверки
trv.ValidationType=ValidationType.xdr;
// Добавить обработчик события проверки
trv.ValidationEventHandler += new ValidationEventHandler(this.ValidationEvent);
// Считываем узел за раз
while(trv.Read()) {
if (trv.NodeType == XmlNodeType.Text) listBox1.Items.Add(trv.Value);
}
}
public void ValidationEvent(object sender, ValidationEventArgs args) {
MessageBox.Show(args.Message);
}
Мы создаем
XmlTextReader для передачи в
XmlValidationReader. Когда
XmlValidationReader trv создан, можно использовать его по большей части так же, как
XmlTextReader в предыдущих примерах. Различия состоят в том что в данном случае определен атрибут
ValidationType и добавлен
ValidationEventHandler. Каждый раз при возникновении ошибки проверки инициируется
ValidationEvent. Затем можно будет обработать ошибку проверки любым приемлемым способом. В данном примере выводится
MessageBox с описанием ошибки. Вот как выглядит
MessageBox, когда инициируется
ValdationEvent.

В отличие от некоторых синтаксических анализаторов
XmlValidationReader после возникновения ошибки продолжает считывание. Имеется возможность определить серьезность ошибки проверки. Если окажется, что это серьезная ошибка, то можно остановить чтение.
Свойство
Schemas класса
XmlValidationReader содержит коллекцию
XmlSchemaCollection, которая находится в пространстве имен
System.Xml.Schema. В этой коллекции находятся предварительно загруженные схемы XSD и XDR, что позволяет выполнить очень быструю проверку, (особенно, если нужно проверить несколько документов), так как схему не нужно каждый раз перезагружать. Для получения выигрыша в производительности и создается объект
XmlSchemaCollection. Метод
Add имеет четыре перегружаемые версии. Можно передать объект на основе
XmlSchema, объект на основе
XmlSchemaCollection, строку
string с пространством имен вместе со строкой
string с URL файла схемы и, наконец, строку
string с пространством имен и объектом на основе
XmlReader, который содержит схему.
Запись XML
Класс
XmlTextWriter позволяет записывать XML в поток, файл или объект
TextWriter. Подобно
XmlTextReader он делает это только вперед, некэшируемым образом.
XmlTextWriter можно конфигурировать различным образом, что позволяет определить такие вещи, как наличие или отсутствие отступов, величину отступа, какой использовать символ кавычки в значениях атрибутов, и поддерживаются ли пространства имен. Свойство
DataTypeNamespace определяет, как строго значения типов преобразуются в текст XML. Для этого свойства допустимо значение
urn:schemas-microsoft-com:datatypes, которое поддерживает типы данных XDR, и другое значение www.w3.org/1999/XMLSchema-data-types, которое является схемой W3C типов данных XSD. Чтобы использовать, например, тип данных
TimeSpan, необходимо будет задать это свойство для типов данных XSD.
Приведем простой пример, чтобы увидеть, как может использоваться класс
TextWriter(пример находится в папке
XMLWriterSample1):
private void button1_Click(object sender, System.EventArgs e) {
// измените в соответствии с используемой структурой путей доступа
string fileName="..\\..\\..\\booknew.xml";
//создайте XmlTextWriter
XmlTextWriter tw=new XmlTextWriter(fileName, null);
// задайте форматирование с отступом
tw.Formatting=Formatting.Indented;
tw.WriteStartDocument();
//Начать создание элементов и атрибутов
tw.WriteStartElement("book");
tw.WriteAttributeString("genre", "Mystery");
tw.WriteAttributeString("publicationdate", "2001");
tw.WriteAttributeString("ISBN", "123456789");
tw.WriteElementString("title", "Case of the Missing Cookie");
tw.WriteStartElement("author");
tw.WriteElementString("name", "Cookie Monster");
tw.WriteEndElement();
tw.WriteElementString("price", "9.99");
tw.WriteEndElement();
tw.WriteEndDocument();
// очистить
tw.Flush();
tw.Close();
}
Создадим новый файл
booknew.xml и добавим новую книгу. Объект
XmlTextWriter заменит существующий файл. Вставку нового элемента или узла в существующий документ рассмотрим позже. Экземпляр объекта
XmlTextWriter создается с помощью объекта
FileStream в качестве параметра. Можно также передать строку с именем файла и путем доступа или объект на основе
TextWriter. При задании свойства
Indenting узлы-потомки будут автоматически делать отступ от предка. Метод
WriteStartDocument() помещает объявление документа. Начинаем запись данных. Сначала идет элемент
book. Затем добавляем атрибуты
genre,
publicationdate и
ISBN. После чего записываем элементы
title,
author, и price. Отметим, что элемент
author имеет элемент-потомок
name.
После нажатия на кнопку будет создан следующий файл
booknew.xml:
<?xml version="1 .0"?>
<book genre= "Mystery" publicationdate="2001" ISBN="123456789">
<title>Case of the Missing Cookie</title>
<author>
<name>Cookie Monster</name>
</author>
<price>9,99</price>
</book>
Так же как в документе XML, здесь имеются начальный метод и конечный метод (
WriteStartElement и
WriteEndElement). Вложенность контролируется отслеживанием начала и окончания записи элементов и атрибутов. Это можно видеть при добавлении элемента потомка
name к элементу
authors. Отметим, как организуются вызовы методов
WriteStartElement и
WriteEndElement и как это связывается с выведенным документом XML.
В дополнение к
WriteElementString и
WriteAtributeString имеется несколько других специализированных методов записи. Метод
WriteCDate будет выводить раздел
CDate (<!CDATE[...]]>), взяв текст для записи из параметра. WriteComment записывает комментарий в подходящем формате XML. WriteChars записывает содержимое символьного буфера. Это работает аналогично методу
ReadChars, который был рассмотрен ранее. Оба они используют один и тот же тип параметров. Методу
WriteChar нужен буфер (массив символов), начальная позиция для записи (целое значение) и число символов для записи (целое значение).
Чтение и запись XML с помощью классов, основанных на
XMLReader и XMLWriter, осуществляются очень просто. Далее мы рассмотрим реализацию DOM пространства имен
System.Xml. Это классы на основе
XmlDocument и
XmlNode.
Объектная модель документа в .NET
Реализация объектной модели документа (DOM, Document Object Model) в .NET поддерживает спецификации W3C DOM Level 1 и Core DOM Level 2. DOM реализуется с помощью класса
XmlNode.
XmlNode является абстрактным классом, который представляет узел документа XML.
XmlNodeList является упорядоченным списком узлов. Это живой список узлов, и любые изменения в любом узле немедленно отражаются в списке.
XmlNodeList поддерживает индексный доступ или итеративный доступ. Эти два класса составляют основу реализации DOM на платформе .NET. Вот список классов, которые основываются на
XmlNode.
| Имя класса |
Описание |
XmlLinkedNode |
Расширяет XmlNode. Возвращает узел непосредственно перед или после текущего узла. Добавляет свойства NextSibling и PreviousSibling в XmlNode. |
XmlDocument |
Расширяет XmlNode. Представляет весь документ. Реализует спецификации DOM Level 1 и Level 2. |
XmlAttribute |
Расширяет XmlNode. Объект атрибута объекта XmlElement. |
XmlCDataSection |
Расширяет XmlCharacterData. Объект, который представляет раздел документа CData. |
XmlCharacterData |
Абстрактный класс, который предоставляет методы манипуляции с текстом для других классов. Расширяет XmlLinkedNode. |
XmlComment |
Расширяет XmlCharacterData. Представляет объект комментария XML. |
XmlDeclaration |
Расширяет XmlLinkedNode. Представляет узел объявления (<?xml version='1.0' ...>) |
XmlDocumentFragment |
Расширяет XmlNode. Представляет фрагмент дерева документа. |
XmlDocumentType |
Расширяет XmlLinkedNode. Данные, связанные с объявлением типа документа. |
XmlElement |
Расширяет XmlLinkedNode. Объект элемента XML. |
XmlEntity |
Расширяет XmlNode. Синтаксически разобранный или неразобранный узел сущности. |
XmlEntityReferenceNode |
Расширяет XmlLinkedNode. Представляет ссылочный узел сущности |
XmlNotation |
Расширяет XmlNode. Содержит нотацию, объявленную в DTD или в схеме. |
XmlProcessingInstruction |
Расширяет XmlLinkedNode. Содержит инструкцию обработки XML. |
XmlSignificantWhitespace |
Расширяет XmlCharacterData. Представляет узел с разделителем. Узлы создаются, только если флаг PreserveWhiteSpace задан как true. |
XmlWhitespace |
Расширяет XmlCharacterData. Представляет разделитель в содержимом элемента. Узлы создаются, только если флаг PreserveWhiteSpace задан как true. |
XmlText |
Расширяет XmlCharacterData. Текстовое содержимое элемента или атрибута. |
Как можно видеть .NET делает доступным класс, соответствующий почти любому типу XML. Мы не будем рассматривать каждый класс подробно, но разберем несколько примеров. Вот как выглядит диаграмма наследования:

Первый пример будет создавать объект
XmlDocument, загружать документ с диска и загружать окно списка с данными из элементов
title. Это аналогично одному из примеров, которые были выполнены в разделе
XmlReader. Отличие заключается в том, что осуществляется выбор, с какими узлами мы хотим работать, вместо того чтобы использовать весь документ. Вот код для выполнения этого в среде
XmlNode. Посмотрите, как просто он выглядит при сравнении (файл можно найти в папке
DOMSample1 загруженного архива):
private void button1_Click(object sender. System.EventArgs e) {
// doc объявлен на уровне модуля
// изменить путь доступа в соответствии со структурой путей доступа
doc.Load("..\\..\\..\\books.xml")
// получить только те узлы, которые нужны
XmlNodeList nodeLst=doc.GetElementsByTagName("title");
// итерации по списку XmlNodeList
foreach(XmlNode node in nodeLst) listBox1.Items.Add(node, InnerText);
}
Обратите внимание, что мы добавили следующее объявление на уровне модуля:
private XmlDocument doc=new XmlDocument();
Если бы это было все, что нужно делать, то использование
XmlReader было бы значительно более эффективным способом загрузки окна списка. Причина в том, что мы прошли через документ один раз и затем закончили с ним работу. Однако, если желательно повторно посетить узел, то использование
XmlDocument является лучшим для этого способом. Слегка расширим пример (новая версия находится в
DOMSample2):
private void button1_Click(object sender, System.EventArgs e) {
//doc объявлен на уровне модуля
// измените путь доступа в соответствии со структурой путей доступа
doc.Load("..\\..\\..\\books.xml");
// получить только те узлы, которые хотим XmlNodeList
nodeLst=doc.GetElementsByTagName("title");
// итерации через список XmlNodeList
foreach(XmlNode node in nodeLst) listBox1.Items.Add(node.InnerText);
}
private void listBox1_SelectedIndexChanged(object sender, System.EventArgs e) {
// создать строку поиска XPath
string srch="bookstore/book[title='" + listBox1.SelectedItem.ToString() + "']";
// поиск дополнительных данных
XmlNode foundNode=doc.SelectSingleNode(srch);
if (foundNode!=null) MessageBox.Show(foundNode.InnerText);
else MessageBox.Show("Not found");
}
В этом примере
listbox с заголовками загружается из документа
books.xml. Когда мы щелкаем на окне списка, вызывая порождение события
SelectedIndexChange (не забудьте добавить код, присоединяющий обработчик событий в функцию
InitializeComponent), мы берем текст выбранного пункта в
listbox, в данном случае заголовок книги, создаем оператор XPath и передаем его в метод
SelectSingleNode объекта
doc. Он возвращает элемент
book, частью которого является title (foundNode). Выведем для наглядности InnerText узла в окне сообщения. Мы можем продолжать щелкать на элементах в
listbox сколько угодно раз, так как документ загружен и остается загруженным, пока мы его не освободим.
Небольшой комментарий в отношении метода
SelectSingleNode. Это реализация
XPath в классе
XmlDocument. Существуют методы
SelectSingleNode и
SelectNodes. Оба они определены в
XmlNode, на котором основывается
XmlDocument.
SelectSingleNode возвращает
XmlNode, и
SelectNodes возвращает
XmlNodeList. Пространство имен
System.Xml.XPath содержит более насыщенную реализацию
XPath (см. ниже).
Ранее рассматривался пример
XmlTextWriter, который создает новый документ. Ограничение состояло в том, что он не вставлял узел в текущий документ. Это можно сделать с помощью класса
XmlDocument. Если изменить
button1_Click из предыдущего примера, то получим следующий код (
DOMSample3):
private void button1_Click(object sender, System.EventArgs e) {
// изменить путь доступа, как требуется существующей структурой
doc.Load("..\\..\\..\\books.xml");
// создать новый элемент 'book'
XmlElement newBook=doc.CreateElement("book");
// задать некоторые атрибуты
newBook.SetAttribute("genre", "Mystery");
newBook.SetAttribute("publicationdate", "2001");
newBook.SetAttricute("ISBN", "123456789");
// создать новый элемент 'title'
XmlElement newTitle=doc.CreateElement("title");
newTitle.InnerText="Case of the Missing cookie";
newBook.AppendChild(newTitle);
// создать новый элемент author
XmlElement newAuthor=doc.CreateElement("author");
newBook.AppendChild(newAuthor);
// создать новый элемент name
XmlElement newName=doc.CreateElement("name");
newName.InnerText="С. Monster";
newAuthor.AppendChild(newName);
// создать новый элемент price
XmlElement newPrice=doc.CreateElement("price");
newPrice.innerText="9.95";
newBook.AppendChild(newPrice);
// добавить к текущему документу
doc.DocumenElement.AppendChild(newBook);
// записать doc на диск
XmlTextWriter tr=new XmlTextWriter("..\\..\\..\\booksEdit.xml", null);
tr.Formatting=Formatting.Indented;
doc.WriteContentTo(tr);
tr.Close();
// загрузить listBox1 со всеми заголовками, включая новый
XmlNodeList nodeLst=doc.GetElementsByTagName("title");
foreach(XmlNode node in nodeLst) listBox1.Items.Add(node.InnerText);
}
private void listBox1_SelectedIndexChanged(object sender, System.EventArgs e) {
string srch="bookstore/book[title='" + listBox1.SelectedItem.ToString() + "']";
XmlNode foundNode=doc.SelectSingleNode(srch);
if (foundNode!=null) MessageBox.Show(foundNode.InnerText);
else MessageBox.Show("Not found");
}
При выполнении этого кода будет получена функциональность предыдущего примера, но в окне списка появилась одна дополнительная книга "The Case of Missing Cookie". Щелчок мыши на заголовке этой книги приведет к выводу такой же информации, как и для других книг. Анализируя код, можно увидеть, что это достаточно простой процесс. Прежде всего создается новый элемент
book:
XmlElement newBook = doc.CreateElement("book);
Метод
CreateElement имеет три перегружаемые версии, которые позволяют определить имя элемента, имя и пространство имен URI, и, наконец,
prefix (префикс),
lоcalname (локальное имя) и
namespace (пространство имен). Когда элемент создан, необходимо добавить атрибуты
newBook.setAttribute("genre", "Mystery");
newBook.SetAttribute("publicationdate", "2001");
newBook.SetAttribute("ISBN", "123456789");
Напомним, что класс
XmlAttribute расширяет класс
XmlNode, поэтому нам доступны все свойства и методы
XmlNode. Даже если имеется очень сложная структура, то при ее размещении никаких проблем возникать не должно.
Теперь, когда атрибуты созданы и необходимо добавить другие элементы книги:
XmlElement newTitle=doc.CreateElement("title");
newTitle.InnerText="Case of the Missing Cookie";
newBook.AppendChild(newTitle);
Здесь снова создается новый объект на основе
XmlElement (newTitle). Присваиваем свойству
InnerText заголовок новой книги и добавляем потомок к элементу
book. Затем это повторяется для остальных элементов
book. Отметим, что элемент
name добавлен как потомок элемента
author. Это дает нам правильное отношение вложенности.
Наконец, мы добавляем элемент
newBook к узлу
doc.DocumentElement. Это тот же уровень, что и у всех других элементов
book. Мы заменили существующий документ новым, в отличие от
XmlWriter, где можно было только создать новый документ. Последнее, что нужно сделать, это записать новый документ XML на диск. В этом примере мы создаем новый
XmlTextWriter и передаем его в метод
WriteContentTo. Не забудьте вызвать метод
Close на
XmlTextWriter, чтобы сбросить содержимое внутренних буферов и закрыть файл. Методы
WriteContentTo и
WriteTo получают
XmlTextWriter в качестве параметра.
WriteContentTo сохраняет текущий узел и всех потомков в
XmlTextWriter, в то время как
WriteTo сохраняет текущий узел. Так как
doc является объектом на основе
XmlDocument, он представляет весь документ и поэтому будет сохранен. Можно было бы также использовать метод
Save. Он всегда будет сохранять весь документ.
Save имеет четыре перегружаемые версии. Можно определить строку с именем файла и путем доступа, объект на основе класса
Stream, объект на основе класса
TextWriter, или объект на основе
XmlWriter. Именно это было использовано при выполнении примера. Отметим новую запись в конце списка:

Если нужно создать документ с самого начала, можно использовать класс
XmlTextWriter. Можно также использовать
XmlDocument. Какой из них выбрать? Если данные, которые желательно поместить в XML, доступны и готовы для записи, то самым подходящий будет класс
XmlTextWriter. Однако, если необходимо создавать документ XML постепенно, вставляя узлы в различные места, то наиболее приемлемым будет применение
XmlDocument. Вот тот же пример, который только что был рассмотрен, но вместо редактирования текущего документа мы создаем новый документ (
DOMSample4):
private void button1_Click(object sender, System.EventArgs e) {
// создать раздел объявлений
XmlDeclaration newDoc=doc.CreateXmlDeclaration("1.0", null, null);
doc.AppendChild(newDoc);
// создать новый корневой элемент
XmlElement newRoot=doc.CreateElement("newBookstore");
doc.AppendChild(newRoot);
// создать новый элемент 'book'
XmlElement newBook=doc.CreateElement("book");
// создать и задать атрибуты элемента "book"
newBook.SetAttribute("genre","Mystery");
newBook.SetAttribute("publicationdate", "2001");
newBook.SetAttribute("ISBN", "123456789");
// создать элемент 'title'
XmlElement newTitle=doc.CreateElement("title");
newTitle.InnerText="Case of the Missing Cookie";
newBook.AppendChild(newTitle);
// создать элемент author
XmlElement newAuthor=doc.CreateElement("author");
newBook.AppendChild(newAuthor);
// создать элемент name
XmlElement newName=doc.CreateElement("name");
newName.InnerText="C. Monster";
newAuthor.AppendChild(newName);
// создать элемент price
XmlElement newPrice=doc.CreateElement("price");
newPrice.InnerText="9.95";
newBook.AppendChild(newPrice);
// добавить элемент 'book' к doc
doc.DocumentElement.AppendChild(newBook);
// записать на диск Note новое имя файла booksEdit.xml
XmlTextWriter tr=new XmlTextWriter("..\\..\\..\\booksEdit.xml", null);
tr.Formatting=Formatting.Indented; doc.WriteContentTo(tr);
tr.Close();
// загрузить заголовок в окно списка
XmlNodeList nodeLst=doc.GetElementsByTagName("title");
foreach(XmlNode node in nodeLst) listBox1.Items.Add(node.InnerText);
}
private void listBox1_SelectedIndexChanged(object sender, System.EventArgs e) {
String srch="newBookstore/book[title='"+ listBox1.SelectedItem.ToString() + "']";
XmlNode foundNode=doc.SelectSingleNode(srch);
if (foundNode!=null) MessageBox.Show(foundNode.InnerText);
else MessageBox.Show("Not found");
}
Заметим, что изменились только две начальные строки. Прежде чем сделать
doc.Load, внесем новые элементы:
XmlDeclaration newDoc=doc.CreateXmlDeclaration("1.0", null, null);
doc.AppendChild(newDoc);
XmlElement newRoot=doc.CreateElement("newBookstore");
doc.AppendChild(newRoot);
Сначала создается новый объект
XmlDeclaration. Параметрами являются версия (в настоящее время всегда
"1.0"), кодировка (
null подразумевает
UTF-8) и, наконец, флаг
standalone. Он может быть
yes или
no, но если вводится null или пустая строка, как в нашем случае, этот атрибут не будет добавляться при сохранении документа. Параметр кодировки должен задаваться строкой, которая является частью класса
System.Text.Encoding, если не используется
null.
Следующим создаваемым элементом станет
DocumentElement. В данном случае мы называем его
newBookstore, чтобы можно было видеть различие. Остальная часть кода является такой же, как и в предыдущем примере, и работает точно так же. Вот файл
booksEdit.xml, создаваемый этим кодом:
<?xml version="1.0"?>
<newBookstore>
<book genre="Mystery" publicationdate="2001" ISBN="123456789">
<title>Case of the Missing Cookie</title>
<author>
<name>C. Monster</name>
</author>
<price>9.95</price>
</book>
</newBookstore>
Мы не рассмотрели всех особенностей класса
XmlDocument или других классов, способствующих созданию модели DOM в .NET. Однако мы видели мощь и гибкость, которые предлагает реализация DOM в .NET. Класс
XmlDocument обычно используется, когда требуется случайный доступ к документу. Используйте классы на основе
XmlReader, когда желательна модель потокового типа. Помните, что гибкость
XmlDocument на основе
XmlNode обеспечивается более высокими требованиями к памяти, поэтому подумайте тщательно о том, какой метод предпочтительнее в конкретной ситуации.
XPath и XslTransform
Мы рассмотрим
XPath и
XslTransform вместе, хотя они являются отдельными пространствами имен на платформе.
XPath содержится в
System.Xml.XPath, a
XslTransform находится в
System.Xml.Xsl. Причина совместного рассмотрения состоит в том, что
XPath, в частности класс
XPathNavigator, предоставляет ориентированный на производительность способ выполнения
XSLTransform в .NET. Для начала рассмотрим
XPath, а затем его использование в классах
System.Xsl.
XPath
Пространство имен
XPath создается для скорости. Оно позволяет только читать документы XML без возможностей редактирования.
XPath создается для поверхностного выполнения быстрых итераций и выбора в документе XML. Функциональность
XPath представляется классом
XPathNavigator. Этот класс может использоваться вместо
XmlDocument,
XmlDataDocument и
XPathDocument. Если требуются средства редактирования, то следует выбрать
XmlDocument; при работе с ADO.NET будет использоваться класс
XmlDataDocument (мы увидим его позже в этой главе). Если имеет значение скорость, то применяйте в качестве хранилища
XPathDocument. Можно расширить
XPathNavigator для таких вещей, как файловая система или реестр в качестве хранилища. В следующей таблице перечислены классы
XPath с кратким описанием назначения каждого класса:
| Имя класса |
Описание |
XPathDocument |
Представление всего документа XML. Только для чтения. |
XPathNavigator |
Предоставляет навигационные возможности для XPathDocument. |
XPathNodeIterator |
Обеспечивает итерацию по множеству узлов. Является эквивалентом для множества узлов в Xpath. |
XPathExpression |
Компилированное выражение Xpath. Используется SelectNodes, SelectSingleNodes, Evaluate и Matches. |
XPathException |
Класс исключений XPath. |
XPathDocument не предлагает никакой функциональности класса
XmlDocument. Он имеет четыре перегружаемые версии, позволяющие открывать документ XML из файла или строки пути доступа, объекта
TextReader, объекта
XmlReader или объекта на основе
Stream.
Загрузим документ
books.xml и поработаем с ним, чтобы можно было понять, как действует навигация. Чтобы использовать эти примеры, необходимо добавить ссылки на пространства имен
System.Xml.Xsl и
System.Xml.XPath следующим образом:
using System.Xml.XPath;
using System.Xml.Xsl;
Для данного примера воспользуемся файлом
bookspath.xml. Он аналогичен
books.xml, за исключением того, что добавлены дополнительные книги. Вот код формы, который находится в папке
XPathXSLSample1:
private void button1_Click(object sender, System.EventArgs e) {
// изменить в соответствии с используемой структурой путей доступа
XPathDocument doc=new XPathDocument("..\\..\\..\\booksxpath.xml");
// создать XPathNavigator
XPathNavigator nav=((IXPathNavigable)doc).CreateNavigator();
// создать XPathNodeIterator узлов книг
// который имеют значение атрибута genre, совпадающее с novel
XPathNodeIterator iter=nav.Select("/bookstore/book[@genre='novel']");
while(iter.MoveNext()) {
LoadBook(iter.Current);
}
}
private void LoadBook(XPathNavigator lstNav) {
// Нам передали XPathNavigator определенного узла book,
// мы выберем всех прямых потомков и
// загрузим окно списка с именами и значениями
XPathNodeIterator iterBook=lstNav.SelectDescendants(XPathNodeType.Element, false);
while(iterBook.MoveNext())
listBox1.Items.Add(iterBook.Current.Name + ": " + iterBook.Current.Value);
}
Здесь сначала создается
XPathDocument, передавая строку файла и пути доступа документа, который будет открыт. В следующей строке кода создается
XPathNavigator:
XPathNavigator nav=((IXPathNavigable)doc).CreateNavigator();
Отметим, что здесь происходит преобразование типа интерфейса
IXPathNavigable в только что созданный
XPathNavigator, что вызывает метод
CreateNavigator. После создания объекта
XPathNavigator можно начать навигацию в документе.
Этот пример показывает, как применяются методы
Select для получения множества узлов, которые имеют
novel в качестве значения атрибута
genre. Затем мы используем цикл
MoveNext() для итераций по всем
novels в списке книг.
Для загрузки данных в
listbox используется свойство
XPathNodeIterator.Current. При этом создается новый объект
XPathNavigator на основе узла, на который указывает
XPathNodeIterator. В данном случае создается
XPathNavigator для одного узла
book (книги) в документе.
LoadBook создает другой
XPathNodeIterator, вызывая иной тип метода выбора — метод
SelectDescendants. Это даст нам
XPathNodeIterator всех узлов-потомков и потомков узлов-потомков узла
book (книга), переданного в метод
LoadBook. Мы делаем другой цикл
MoveNext() на этом
XPathNodeIterator и загружаем окно списка именами и значениями элементов.
XPathNavigator содержит все методы для перемещения и выбора элементов, которые могут понадобиться. Приведем некоторые из методов перемещения:
| Имя метода |
Описание |
| MoveTo |
Получает в качестве параметра XPathNavigator. Делает текущей позицию, которая указана в XPathNavigator. |
MoveToAttribute |
Перемещает к именованному атрибуту. Получает имя атрибута и пространство имен как параметры. |
MoveToFirstAttribute |
Перемещает к первому атрибуту текущего элемента. Возвращает true, если выполняется успешно. |
MoveToNextAttribute |
Перемещает к следующему атрибуту текущего элемента. Возвращает true, если выполняется успешно. |
MoveToFirst |
Перемещает к первому sibling текущего узла. Возвращает true, если выполняется успешно, в противном случае возвращает false. |
MoveToLast |
Перемещает к последнему sibling текущего узла. Возвращает true, если выполняется успешно. |
MoveToNext |
Перемещает к следующему sibling текущего узла. Возвращает true, если выполняется успешно. |
MoveToPrevious |
Перемещает к предыдущему sibling текущего узла. Возвращает true, если выполняется успешно. |
MoveToFirstChild |
Перемещает к первому потомку текущего элемента. Возвращает true, если выполняется успешно. |
MoveToId |
Перемещает к элементу с идентификатором ID, предоставленным в виде параметра. Должна существовать схема документа и данные элемента типа ID. |
MoveToParent |
Перемещает к предку текущего узла. Возвращает true, если выполняется успешно. |
MoveToRoot |
Перемещает к корневому узлу документа. |
Существует также несколько методов
Select выбора подмножества узлов для работы. Все методы
Select возвращают объект
XPathNodeIterator.
XPathNodeIterator можно считать эквивалентом
NodeList или
NodeSet в
XPath. Этот объект имеет три свойства и два метода:
□
Clone — создает новую копию себя
□
Count — число узлов в объекте
XPathNodeIterator
□
Current — возвращает
XPathNavigator, указывающий на текущий узел
□
CurrentPosition — возвращает целое число, соответствующее текущей позиции
□
MoveNext — перемещает в следующий узел, соответствующий выражению
Xpath, которое создало
XPathNodeIterator
Можно использовать также существующие методы
SelectAncestors и
SelectChildren. Они возвращают
XPathNodelterator. В то время, как
Select получает выражение
XPath в качестве параметра, другие методы выбора получают в качестве параметра
XPathNodeType. В рассматриваемом примере мы выбираем все узлы
XPathNodeType.Element.
Вот как выглядит экран после выполнения кода. Обратите внимание, что все перечисленные книги являются романами (novel).

Для добавления стоимости книг
XPathNavigator содержит метод
Evaluate.
Evaluate имеет три перегружаемые версии. Первая из них содержит строку, которая является вызовом функции
XPath. Вторая перегружаемая версия Evaluate использует в качестве параметра объект
XPathExpression, третья —
XPathExpression и
XPathNodeIterator. Сделаем следующие изменения в примере (эту версию кода можно найти в
XPathXSLSample2):
private void button1_Click(object sender, System.EventArgs e) {
//изменить в соответствии со структурой путей доступа
XPathDocument doc=new XPathDocument("..\\..\\..\\booksxpath.XML");
//создать XPathNavigator
XPathNavigator nav=((IXPathNavigable)doc).CreateNavigator();
//создать XPathNodeIterator узлов book,
// которые имеют novel значением атрибута genre
XPathNodeIterator iter=nav.Select("/bookstore/book[@genre="novel']");
while(iter.MoveNext()) {
LoadBook(iter.Current.Clone());
}
// добавим разделительную линию и вычислим сумму
listBox1.Items.Add("========================");
listBox1.Items.Add("Total Cost = "
+ nav.Evaluate("sum(/bookstore/book[@genre='novel']/price)"));
}
При этом вывод изменится следующим образом:
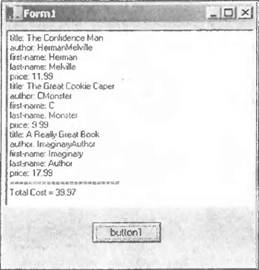
XslTransform
Пространство имен
System.Xml.Xsl содержит классы XSL, применяемые .NET.
XslTransform может использоваться с любым хранилищем, которое реализует интерфейс
IXPathNavigable. В настоящее время на платформе .NET это:
XmlDocument,
XmlDataDocument и
XPathDocument. Так же как и в случае XPath, воспользуйтесь тем хранилищем, которое подходит лучшим образом. Если планируется создание заказного хранилища, такого как файловая система, и желательно иметь возможность выполнять преобразования, не забудьте реализовать в классе интерфейс
IXPathNavigable.
XslTransform основывается на потоковой модели запросов. В связи с этим можно соединить несколько преобразования вместе. Можно даже применять, если нужно, между преобразованиями заказной объект чтения. Это предоставляет большую гибкость при проектировании.
В первом примере, который мы рассмотрим, берется документ
books.xml и преобразуется в простой документ HTML для вывода. (Этот код можно найти в папке
XPathXSLSample3.) Необходимо будет добавить следующие операторы
using:
using System.IO;
using System.Xml.Xsl;
using System.Xml.XPath;
Вот код, выполняющий преобразование:
private void button1_Click(object sender System.EventArgs e) {
//создать новый XPathDocument
XPathDocument doc=new XPathDocument("..\\..\\..\\booksxpath.XML");
// создать новый XslTransForm
XslTransform transForm=new XslTransform();
transForm.Load("..\\..\\..\\books.xsl");
// этот FileStream будет нашим выводом
FileStream fs=new FileStream("..\\..\\..\\booklist.html", FileMode.Create);
// Создать Navigator
XPathNavigator nav=((IXPathNavigable)doc).CreateNavigator();
// Выполнить преобразование. Файл вывода создается здесь.
transForm.Transform(nav, null, fs);
}
Сделать это преобразование проще почти невозможно. Сначала создается объект на основе
XPathDocument и объект на основе
XslTransform. Затем файл
bookspath.xml загружается в
doc, a
books.xsl в
transForm. В этом примере для записи нового документа HTML на диск создается объект
FileStream.
Если бы это было приложение ASP.NET, мы использовали бы объект
TextWriter и передавали бы его в объект
HttpResponse. Если бы мы преобразовывали в другой документ XML, то применялся бы объект на основе
XmlWriter. После того как объекты
XPathDocument и
XslTransform будут готовы, мы создаем
XPathNavigator на
doc и передаем
nav и этот
stream в метод
Transform объекта
transForm.
XslTransform имеет несколько перегружаемых версий, получающих комбинации навигаторов,
XsltArgumentList (подробнее об этом позже) и потоков ввода/вывода. Параметром навигатора может быть
XPathNavigator или любой объект, реализующий интерфейс
IXPathNavigable. Потоки ввода/вывода могут быть
TextWriter,
Stream или объектом на основе
XmlWriter.
Документ
books.xsl является таблицей стилей. Документ выглядит следующим образом:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<head>
<title>Price List</title>
</head>
<body>
<table>
<xsl:apply-templates/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="bookstore">
<xsl:apply-templates select= "book"/>
</xsl:template>
<xsl:template match="book">
<tr><td>
<xsl:value-of select="title"/>
</td><td>
<xsl:value-of select="price"/>
</td></tr>
</xsl:template>
</xsl:stylesheet>
Ранее упоминался объект
XsltArgumentList. Это способ, которым можно объект с методами связать с пространством имен. Когда это сделано, можно вызывать методы во время преобразования. Рассмотрим пример, чтобы понять, как это работает (находится в
XPathXSLSample4):
private void button1_Click(object sender, System.EventArgs e) {
// новый XPathDocument
XPathDocument doc=new XPathDocument("..\\..\\..\\booksxpath.xml");
// новый XslTransform
XslTransform transForm=new XslTransform();
transForm.Load("..\\..\\..\\booksarg.xsl");
// новый XmlTextWriter, так как мы создаем новый документ xml
XmlWriter xw=new XmlTextWriter(..\\..\\..\\argSample.xml", null);
// создать XslArgumentList и новый объект BookUtils
XsltArgumentList argBook=new XsltArgumentList();
BookUtils bu=new BookUtils();
// это сообщает список аргументов BookUtils
argBook.AddExtensionObject("urn:ProCSharp", bu);
// новый XPathNavigator
XPathNavigator nav=((IXPathNavigable)doc).CreateNavigator();
// выполнить преобразование
transForm.Transform(nav, argBook, xw);
xw.Close();
}
// простой тестовый класс
public class BookUtils {
public BookUtils() {}
public string ShowText() {
return "This came from the ShowText method!";
}
}
Вывод преобразования (
argSample.xml) выглядит так:
<?xml version="1.0"?>
<books>
<discbook>
<booktitle>The Autobiography of Benjamin Franklin</booktitle>
<showtext>This came from the ShowText method!</showLext>
</discbook>
<discbook>
<booktitle>The Confidence Man</booktitle>
<showtext>This came from the ShowText method!</showtext>
</discbook>
<discbook>
<booktitle>The Gorgias</booktitle>
<showtext>This came from the ShowText method!</showtext>
</discbook>
<discbook>
<booktitle>The Great Cookie Caper</booktitle>
<showtext>This came from the ShowText method!</showtext>
</discbook>
<discbook>
<booktitle>A Really Great Book</booktitle>
<showtext>This came from the ShowText method!</showtext>
</discbook>
</books>
Определим новый класс
BookUtils. В этом классе мы имеем один практически бесполезный метод, который возвращает строку
"This came from the ShowText method!". Для события
button1_Click создаются
XPathDocument и
XslTransform так же, как это делалось раньше, но с некоторыми исключениями. В этот раз мы собираемся создать документ XML, поэтому используем
XMLWriter вместо
FileStream. Вот эти изменения:
XsltArgumentList argBook=new XsltArgumentList();
BookUtils bu=new BookUtils();
argBook.AddExtensionObject("urn:ProCSharp", bu);
Именно здесь создается
XsltArgumentList. Мы создаем экземпляр объекта
BookUtils, и когда вызывается метод
AddExtensionObject, ему передается пространство имен расширения и объект, из которого мы хотим вызывать методы. Когда делается вызов
Transform, ему передаются
XsltArgumentList (
argBook) вместе с
XPathNavigator и созданный объект
XmlWriter. Вот документ
booksarg.xsl:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:bookutil="urn:ProCSharp">
<xsl:output method="xml" indent="yes"/>
<xsl:template match="/">
<xsl:element name="books">
<xsl:apply-templates/>
</xsl:element>
</xsl:template>
<xsl:template match="bookstore">
<xsl:apply-templates select="book"/>
</xsl:template>
<xsl:template match="book">
<xsl:element name="discbook">
<xsl:element name="booktitle">
<xsl:value-of select="title"/>
</xsl:element>
<xsl:element name="showtext">
<xsl:value-of select="bookUtil:ShowText()"/>
</xsl:element>
</xsl:element>
</xsl:template>
</xsl:stylesheet>
Здесь имеются две важные строки. В начале добавляется пространство имен, которое создается при добавлении объекта к
XsltArgumentList. Затем применяется стандартный синтаксис использования префикса перед пространством имен XSLT и вызывается метод.
Иначе это можно было бы выполнить с помощью сценария XSLT. В таблицу стилей можно включить код C#, VB и JavaScript. Большим достоинством этого является то, что в отличие от текущих реализаций, сценарий компилируется при вызове
Transform.Load; таким образом выполняются уже откомпилированные сценарии, в значительной степени так же, как работает ASP.NET. Давайте выполним предыдущий пример таким способом. Добавим сценарий к таблице стилей. Эти изменения можно увидеть в файле
bookscript.xsl:
<xsl:stylesheet version="1.0" xmlns:Xsl="http://www.w3.org/1999/XSL/Transform" xmlns:msxsl="urn:schemas-microsoft-com:xslt" xmlns:user="http://wrox.com">
<msxsl:script language="C#" implements-prefix="user">
string ShowText() {
return "This came from the ShowText method!";
}
</msxsl:script>
<xsl:output method="xml" indent="yes"/>
<xsl:template match="/">
<xsl:element name="books">
<xsl:apply-templates/>
</xsl:element>
</xsl:template>
<xsl:template match="bookstore">
<xsl:apply-templates select="book"/>
</xsl:template>
<xsl:template match="book">
<xsl:element name="discbook">
<xsl:element name="booktitle">
<xsl:value-of select="title"/>
</xsl:element>
<xsl:element name="showtext">
<xsl:value-of select="user:ShowText()"/>
</xsl:element>
</xsl:element>
</xsl:template>
</xsl:stylesheet>
Изменения включают задание пространства имен сценариев, добавление кода (который скопирован из VS.NET IDE) и выполнение вызова в таблице стилей. Вывод выглядит так же, как и в предыдущем примере.
Ключевой момент, о котором необходимо помнить при выполнении преобразований, состоит в том, чтобы не забыть использовать подходящее хранилище;
XPathDocument, если не требуется редактирование,
XmlDataDocument, если данные получают из ADO.NET, и
XmlDocument, если необходимо иметь возможность редактировать данные. Процесс будет таким же, несмотря ни на что.
XML и ADO.NET
XML является средством, которое связывает ADO.NET с остальным миром. ADO.NET был создан для работы внутри среды XML. XML используется для преобразования данных в и из хранилища данных в приложение или страницу Web. Так как ADO.NET использует XML в качестве транспорта, то данными можно обмениваться с приложениями и системами, которые даже не знают об ADO.NET. Пока обрабатывается XML, они могут совместно использовать данные. ADO.NET может читать документы XML, возвращаемые из этих же приложений. В связи с важностью XML для ADO.NET, существует ряд полезных свойств ADO.NET, которые позволяют чтение и запись документов XML. Пространство имен XML содержит также классы, которые могут потреблять или утилизировать реляционные данные ADO.NET.
Данные ADO.NET в документе XML
Первый пример, который будет рассмотрен, использует потоки ADO.NET и XML для извлечения данных из базы данных
Northwind в
DataSet, загрузки объекта
XmlDocument, содержащего XML, из
DataSet, и загрузки XML в listbox аналогично тому, что делалось ранее. Чтобы выполнить несколько следующих примеров, необходимо добавить инструкции
using:
using System.Data;
using System.Xml;
using System.Data.SqlClient;
using System.IO;
Также для примеров ADO в формы добавлены
DataGrid, что позволит нам увидеть данные в
DataSet из ADO.NET, так как они ограничены сеткой, а также данные из созданных документов XML, которые загружаются в
listbox. Вот код первого примера, который можно найти в папке
ADOSample1:
private void button1_Click(object sender, System.EventArgs e) {
// создать множество данных DataSet
DataSet ds=new DataSet("XMLProducts");
// соединиться с базой данных northwind и
//выбрать все строки из таблицы продуктов
//убедитесь, что имя пользователя соответствует версии SqlServer
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter da=new SqDataAdapter("select * from products", conn);
После создания
SqlDataAdapter,
da и
DataSet,
ds создаются экземпляры объекта
MemoryStream, объекта
StreamReader и объекта
StreamWriter. Объекты
StreamReader и
StreamWriter будут применять
MemoryStream для перемещения XML:
MemoryStream memStrm=new MemoryStream();
StreamReader strmRead=new StreamReader(memStrm);
StreamWriter strmWrite=new StreamWriter(memStrm);
Мы будем использовать
MemoryStream, поэтому ничего на диск записываться не будет, однако мы сможем применять любые объекты на основе класса
Stream, такие как
FileStream. Затем мы заполним
DataSet и свяжем его с
DataGrid. Данные из
DataSet будут выводиться теперь в
DataGrid:
da.Fill(ds, "products");
// загрузка данных в DataGrid
dataGrid1.DataSource=ds;
dataGrid1.DataMember="products";
На следующем шаге генерируется XML. Вызывается метод
WriteXml из класса
DataSet.
WriteXml генерирует документ XML. Существуют две перегружаемые версии
WriteXml, одна получает строку с путем доступа и именем файла, а в другом методе добавлен параметр режима
mode. Этот
mode является перечислением
XmlWriteMode. Возможными значениями являются
DiffGram,
IgnoreSchema, и
WriteSchema. Обсудим
DiffGram позже в этом разделе.
IgnoreSchema используется, если нежелательно, чтобы
WriteXml записывал подставляемую (
inline) схему в файл XML; используйте параметр
WriteSchema, если это желательно. Чтобы получить именно схему, вызывается
WriteXmlSchema. Этот метод имеет четыре перегружаемые версии. Одна получает строку, содержащую путь доступа и имя файла, куда записывается документ XML. Вторая версия использует объект, который основывается на классе
XmlWriter. Третья версия использует объект, который основывается на классе
TextWriter. Четвертая версия используется в примере, параметр в этом случае является производным от класса Stream:
ds.WriteXml(strmWrite, XmlWriteMode.IgnoreSchema);
memStrm.Seek(0, SeekOrigin, Begin);
// читаем из потока в памяти в объект XmlDocument
doc.load(strmRead);
// получить все элементы продуктов
XmlNodeList nodeLst=doc.GetElementsByTagName("ProductName");
// загрузить их в окно списка
foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerText);
}
private void listBox1_SelectedIndexChanged(object sender, System.EventArgs e) {
// при щелчке в окне списка
// появляется окно сообщения с ценой изделия
string srch=
"XmlProducts/products[ProductName= " + '"' + listBox1.SelectedItem.ToString() + "]";
XmlNode foundNode=doc.SelectSingleNode(srch);
if (foundNode!=null)
MessageBox.Show(foundNode.SelectSingleNode("UnitPrice").InnerText);
else MessageBox.Show("Not found");
}
На следующем экране можно видеть данные в списке, а также в таблице данных:

Если желательно сохранить документ XML на диске, то нужно сделать примерно следующее:
string file = "с:\\test\\product.xml";
ds.WriteXml(file);
Это даст нам правильно сформированный документ XML на диске, который можно прочитать посредством другого потока, с помощью
DataSet, или может использоваться другим приложением или web-сайтом. Так как никакого параметра
XmlMode не определено, этот документ
XmlDocument будет содержать схему. В нашем примере в качестве параметра для метода
XmlDocument.Load используется поток.
Когда
XmlDocument подготовлен, мы загружаем
listbox с помощью того же объекта
XPath, который использовался раньше. Если посмотреть внимательно, то можно заметить, что слегка изменено событие
listBox1_SelectedIndexChanged. Вместо вывода
InnerText элемента, выполняется другой поиск
XPath с помощью
SelectSingleNode, чтобы получить элемент
UnitPrice. Каждый раз при щелчке на продукте в
listbox будет появляться
MessageBox для
UnitPrise. Теперь у нас есть два представления данных, но более важно то, что имеется возможность манипулировать данными с помощью двух различных моделей. Можно использовать пространство имен Data для данных или пространство имен XML через данные. Такой подход ведет к очень гибким конструкциям в приложениях, так как теперь при программировании нет жесткой связи только с одной объектной моделью. Таким образом, мы имеем несколько представлений одних и тех же данных и несколько способов доступа к данным.
Следующий пример будет упрощать процесс, удаляя три потока и используя некоторые возможности ADO, встроенные в пространство имен XML. Нам понадобится изменить строку кода на уровне модуля:
private XmlDocument doc=new XmlDocument();
на:
private XmlDataDocument doc;
Это нужно сделать, так как мы не собираемся использовать
XmlDataDocument. Вот код, который можно найти в папке
ADOSample2:
private void button1_Click(object sender, System.EventArgs e) {
// создать множество данных (DataSet)
DataSet ds=new DataSet("XMLProducts");
// соединиться с базой данных northwind и
//выбрать все строки из таблицы products
//выполнить изменения в строке подключения с учетом имени пользователя и имени сервера
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter da=new SqlDataAdapter("select * from products", conn);
// заполнить множество данных
da.Fill(ds, "products");
// загрузить данные в сетку
dataGrid1.DataSource=ds;
dataGrid1.DataMember="products";
doc=new XmlDataDocument(ds);
// извлечь все элементы продуктов
XmlNodeList nodeLst=doc.GetElementsByTagName("ProductName");
// загрузить их в окно списка
// здесь используется цикл for
for(int ctr=0; ctr<nodeLst.Count; ctr++) listBox1.Items.Add(nodeLst[ctr].InnerText);
}
Как можно видеть, код для загрузки
DataSet в документ XML был упрощен. Вместо использования класса
XmlDocument, используется класс
XmlDataDocument. Этот класс был создан специально для использования данных с объектом
DataSet.
XmlDataDocument базируется на классе
XmlDocument, поэтому он имеет всю функциональность класса
XmlDocument. Одним из основных отличий является перегруженный конструктор для
XmlDataDocument. Отметим строку кода, где создается экземпляр
XmlDataDocument:
XmlDataDocument doc=new XmlDataDocument(ds);
Он передает в качестве параметра созданный объект
DataSet,
ds. Документ XML создается из множества данных, поэтому не требуется использование метода
Load. Существует также свойство
DataSet, которое может задаваться с помощью текущего свойства
DataSet. Фактически, если создается новый объект
XmlDataDocument без передачи
DataSet в качестве параметра, то он содержит объект
DataSet с именем
NewDataSet, который не имеет
DataTables в коллекции таблиц. Существует также свойство
DataSet, которое можно установить после создания объекта на основе
XmlDataDocument. Если после вызова
DataSet.Fill добавляется следующая строка кода:
ds.WriteXml("с:\\test\\sample.xml" , XmlWriteMode, WriteSchema);
…создается следующий XML. Отметим, что мы включили в документ схему XSD. Если нежелательно, чтобы схема включалась в файл, то можно передать член перечисления
XmlWriteMode.IgnoreSchema:
<?xml version="1.0" standalone="yes"?>
<XMLProducts>
<xsd:schema id="XMLProducts" targetNamespace="" xmlns="" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xsd:element name="XMLProducts" msdata:IsDataSet="true">
<xsd:complexType>
<xsd:choice maxOccurs="unbounded">
<xsd:element name="products">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="ProductID" type="xsd:int" minOccurs="0" />
<xsd:element name="ProductName" type="xsd:string" minOccurs="0" />
<xsd:element name="SupplierID" type="xsd:int" minOccurs ="0" />
<xsd:element name="CategoryID" type="xsd:int" minOccurs="0" />
<xsd:element name="QuantityPerUnit" type="xsd:string" minOccurs="0" />
<xsd:element name="UnitPrice" type="xsd:decimal" minOccurs="0" />
<xsd:element name="UnitsInStock" type="xsd:short" minOccurs="0" />
<xsd:element name="UnitsOnOrder" type="xsd:short" minOccurs="0" />
<xsd:element name="ReorderLevel" type="xsd:short" minOccurs="0" />
<xsd:element name="Discontinued" type="xsd:boolean" minOccurs="0" />
</xsd:sequence>
</xsd:сomplexType>
</xsd:element>
</xsd:choice>
</xsd:complexType>
</xsd:element>
</xsd:schema>
<products>
<ProductID>1</ProductID>
<ProductName>Chai</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>1</CategoryID>
<QuantityPerUnit>10 boxes x 20 bags</QuantityPerUnit>
<UnitPrice>18</UnitPrice>
<UnitsInStock>39</UnitsInStock>
<UnitsOnOrder>0</UnitsOnOrder>
<ReorderLevel>10</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
<products>
<ProductID>2</ProductID>
<ProductName>Chang</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>1</CategoryID>
<QuantityPerUnit>24 - 12 oz bottles</QuantityPerUnit>
<Unitprice>19</UnitPrice>
<UnitsInStock>17</UnitsInStock>
<UnitsOnOrder>40</UnitsOnOrder>
<ReorderLevel>25</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
</XMLProducts>
Показаны только два первых продукта. Реальный файл XML будет содержать все продукты из таблицы
Products базы данных
Northwind.
Это выглядит достаточно просто для одной таблицы, но что будет для реляционных данных, таких как несколько
DataTables и
Relations в
DataSet? Все по-прежнему работает таким же образом. Внесем следующие изменения в коде (эту версию можно найти в
ADOSample3):
private void button1_Click(object sender, System.EventArgs e) {
//создать множество данных (DataSet)
DataSet ds=new DataSet("XMLProducts");
// соединиться с базой данных northwind и
//выбрать все строки из таблицы products и таблицы suppliers
//проверьте, что строка соединения соответствует конфигурации сервера
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter daProd=new SqlDataAdapter("select * from products", conn);
SqlDataAdapter daSup=new SqlDataAdapter("select * from suppliers", conn);
//Заполнить DataSet из обоих SqlAdapters
daProd.Fill(ds, "products");
daSup.Fill(ds, "suppliers");
//Добавить отношение
ds.Relations.Add(ds.Tables["suppliers"].Columns["SupplierId"],
ds.Tables["products"].Columns["SupplierId"]);
//Записать Xml в файл, чтобы можно было просмотреть его позже
ds.WriteXml("..\\..\\..\\SuppProd.xml", XmlWriteMode.WriteSchema);
//загрузить данные в таблицу
dataGrid1.DataSource=ds;
dataGrid1.DataMember="suppliers";
//создать XmlDataDocument
doc=new XmlDataDocument(ds);
//Выбрать элементы productname и загрузить их в таблицу
XmlNodeList nodeLst=doc.SelectNodes("//ProductName");
foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml);
}
В этом примере создаются два объекта
DataTables в
DataSet из
XMLProducts:
Products и
Suppliers. Отношение состоит в том, что
Suppliers (Поставщики) поставляют
Products (Продукты). Мы создаем новое отношение на столбце
SupplierId в обоих таблицах. Вот как выглядит
DataSet:

Делая такой же вызов метода
WriteXml, как в предыдущем примере, мы получим следующий файл XML (
SuppProd.xml):
<?xml version="1.0" standalone="yes"?>
<XMLProducts>
<xsd:schema id="XMLProducts" targetNamespace="" xmlns="" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xsd:element name="XMLProducts" msdata:IsDataSet="true">
<xsd:complexType>
<xsd:choice maxOccurs="unbounded">
<xsd:element name="products">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="Product ID" type="xsd:int" minOccurs="0" />
<xsd:element name="ProductName" type="xsd:string" minOccurs="0" />
<xsd:element name="SupplierID" type="xsd:int" minOccurs="0" />
<xsd:element name="CategoryID" type="xsd:int" minOccurs="0" />
<xsd:element name="QuantityPerUnit" type="xsd:string" minOccurs="0" />
<xsd:element name="UnitPrice" type="xsd:decimal" minOccurs="0" />
<xsd:element name="UnitsInStock" type="xsd:short" minOccurs="0" />
<xsd:element name="UnitsOnOrder" type="xsd:short" minOccurs="0" />
<xsd:element name="ReorderLevel" type="xsd:short" minOccurs="0" />
<xsd:element name="Discontinued" type="xsd:boolean" minOccurs="0" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="suppliers">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="SupplierID" type="xsd:int" minOccurs="0" />
<xsd:element name="CompanyName" type="xsd:string" minOccurs="0" />
<xsd:element name="ContactName" type="xsd:string" minOccurs="0" />
<xsd:element name="ContactTitle" type="xsd:string" minOccurs="0" />
<xsd:element name="Address" type="xsd:string" minOccurs="0" />
<xsd:element name="City" type="xsd:string" minOccurs="0" />
<xsd:element name="Region" type="xsd:string" minOccurs="0" />
<xsd:element name="PostalCode" type="xsd:string" minOccurs="0" />
<xsd:element name="Country" type="xsd:string" minOccurs="0" />
<xsd:element name="Phone" type="xsd:string" minOccurs="0" />
<xsd:element name="Fax" type="xsd:string" minOccurs="0" />
<xsd:element name="HomePage" type="xsd:string" minOccurs="0" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:choice>
</xsd:complexType>
<xsd:unique name="Constraint1">
<xsd:selector xpath=".//suppliers" />
<xsd:field xpath="SupplierID" />
</xsd:unique>
<xsd:keyref name="Relation1" refer="Constraint1">
<xsd:selector xpath=".//products" />
<xsd:field xpath="SupplierID" />
</xsd:keyref>
</xsd:elements>
</xsd:schema>
<products>
<ProductID>1</ProductID>
<ProductName>Chai</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>1</CategoryID>
<QuantityPerUnit>10 boxes x 20 bags</QuantityPerUnit>
<UnitPrice>18</UnitPrice>
<UnitsInStock>39</UnitsInStock>
<UnitsOnOrder>0</UnitsOnOrder>
<ReorderLevel>10</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
<products>
<ProductID>2</ProductID>
<ProductName>Chang</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>1</CategoryID>
<QuantityPerUnit>24 - 12 oz bottles</QuantityPerUnit>
<UnitPrice>19</UnitPrice>
<UnitsInStock>17</UnitsInStock>
<UnitsOnOrder>40<UnitsOnOrder>
<ReorderLevel>25</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
<suppliers>
<SupplierID>1</SupplierID>
<CompanyName>Exotiс Liquids</CompanyName>
<ContactName>Charlotte Cooper</ContactName>
<ContactTitle>Purchasing Manager</ContactTitle>
<Address>49 Gilbert St.</Address>
<City>London</City>
<PostalCode>EC1 4SD</PostalCode>
<Country>UK</Country>
<Phone>(171) 555-2222</Phone>
</suppliers>
<suppliers>
<Supplier ID>2</SupplierID>
<CompanyName>New Orleans Cajun Delights</CompanyName>
<ContactName>Shelley Burke</ContactName>
<ContactTitle>Order Adminisirator</ContactTitle>
<Address>P.O. Box 78934</Address>
<City>New Orleans</City>
<Region>LA</Region>
<PostalCode>70117</PostalCode>
<Country>USA</Country>
<Phone>(100) 555-4822</Phone>
<HomePage>#CAJUN.HTM#</HomePage>
</suppliers>
</XMLProducts>
Эта схема включает в себя обе таблицы данных
DataTables, которые находились в
DataSet. Данные также содержат все данные из обеих таблиц. Несколько продуктов и поставщиков были удалены из окончательного файла, чтобы сэкономить пространство. Как и раньше, можно сохранить только схему или только данные, передавая соответствующий параметр
XmlWriteMode.
Преобразование документа XML в данные ADO.NET
Предположим что имеется документ XML, который нужно поместить в
DataSet ADO.NET. И вы хотите сделать это так. чтобы можно было загрузить XML в базу данных, или, может быть, связать данные с управляющим элементом данных .NET, таким как
DataGrid. Таким образом, можно будет на самом деле использовать документ XML в качестве хранилища данных, и можно будет полностью исключить накладные расходы, связанные с базой данных. Вот некоторый код для начала (
ADOSample4):
private void button1_Click(object sender, System.EventArgs e) {
// создать новое множество данных (DataSet)
DataSet ds=new DataSet("XMLProducts");
//считать документ Xml в Dataset
ds.ReadXml("..\\..\\..\\prod.xml");
//загрузить данные в таблицу
detaGrid1.DataSource=ds;
dataGrid1.DataMember="products";
//создать новый XmlDataDocument
doc=new XmlDataDocument(ds);
//загрузить имена продуктов в окно списка
XmlNodeList nodeLst=doc.SelectNodes("//ProductName");
foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml);
}
Действительно, просто. Создается экземпляр нового объекта
DataSet. Вызывается метод
ReadXml, и XML оказывается в
DataTable в
DataSet. Как и методы
WriteXml,
ReadXml имеет параметр
XmlReadMode и пару дополнительных опций в
XmlReadMode. Они приводятся в следующей таблице:
| Имя перечисления |
Описание |
Auto |
Задает для XmlReadMode наиболее подходящее значение. Если данные находятся в формате DiffGram, выбирается DiffGram. Если схема уже была прочитана, или если обнаружена подставляемая схема, то выбирается ReadSchema. Если с DataSet не связано ни одной схемы и не обнаружена подставляемая схема, то выбирается IgnoreSchema. |
DiffGram |
Считывает в документ DiffGram и применяет изменения к DataSet. DiffGram описан далее в этой главе. |
Fragment |
Считывает документы, которые содержат фрагменты схемы XDR, такие как тип, созданный SQL Server. |
IgnoreSchema |
Игнорирует подставляемую схему, которая может быть обнаружена. Считывает данные в текущую схему DataSet. Если данные не соответствуют схеме DataSet, они отбрасываются. |
InferSchema |
Игнорирует любую подставляемую схему. Создает схему на основе данных в документе XML. Если она существует в DataSet, используется эта схема, расширяемая дополнительными столбцами и таблицами. Если столбец существует, но имеет другой тип данных, порождается исключение. |
ReadSchema |
Считывает подставляемую схему и загружает данные. Не будет перезаписывать схему в DataSet, но будет порождать исключение, если таблица в подставляемой схеме уже существует в DataSet. |
Существует также метод
ReadSchema. Он будет считывать автономную схему и создавать таблицы, столбцы и отношения соответственно. Этот метод используется, если схема не поставляется вместе с данными.
ReadSchema имеет те же четыре перегружаемые версии, строку с именем файла и путем доступа, объект на основе
Stream, объект на основе
TextReader и объект на основе
XmlReader.
Чтобы показать, что таблицы данных будут созданы правильно, загрузим документ XML, который содержит таблицы
Products и
Suppliers, использовавшиеся в предыдущем примере. В этот раз, однако, загрузим в
listbox имена
DataTable, имена
DataColumn и тип данных. Мы можем сравнить это с первоначальной базой данных
Northwind, чтобы убедиться, что все по-прежнему хорошо. Вот код, который будет применяться и который можно найти в
ADOSample5:
private void button1_Click(object sender, System.EventArgs e) {
// создать DataSet
DataSet ds=new DataSet("XMLProducts");
// считать документ xml
ds.ReadXml("..\\..\\..\\SuppProd.xml");
// загрузить данные в сетку
dataGrid1.DataSource=ds;
dataGrid1.DataMember="products";
// загрузить в listbox информацию о таблицах, столбцах и типах данных
foreach(DataTable dt in ds.Tables) {
listBox1.Items.Add(dt.TableName);
foreach(DataColumn col in dt.Columns) {
listBox1.Items.Add('\t' + col.ColumnName + " - " + col.DataType.FullName);
}
}
}
Отметим добавление двух циклов
foreach (выделенных полужирным шрифтом). Первый цикл извлекает имя таблицы из каждой таблицы в коллекции таблиц
DataSet. Внутри цикла
foreach извлекаются имя и тип данных каждого столбца в
DataTable. Эти данные загружаются в
listbox, чтобы их можно было вывести. Вот что мы должны увидеть на экране:

Посмотрев на
listbox, можно увидеть, что
DataTables были созданы с помощью столбцов, которые имеют правильные имена и типы данных.
Кроме того, можно заметить, что последние два примера не преобразуют никаких данных в или из базы данных, таким образом, не определены
SqlDataAdapters или
SqlConnections. Это дает начальное представление о реальной гибкости пространства имен
System.Xml и ADO.NET. Можно посмотреть на одни и те же данные в множестве форматов. Если понадобиться сделать преобразование и показать данные в формате HTML или необходимо связать их с сеткой, возьмите те же самые данные и с помощью вызова метода получите их в нужном формате.
Запись и чтение DiffGram
DiffGram является документом XML, который содержит данные до и после сеанса редактирования, включающего любую комбинацию изменений данных, добавлений и удалений.
DiffGram может использоваться как аудиторский журнал или для процесса подтверждения/отката. Большинство систем DBMS сегодня имеют такое встроенное средство. Но если придется работать с DBMS, которая не имеет таких свойств или если хранилищем данных является XML и отсутствует DBMS, то можно будет самостоятельно реализовать свойства подтверждения/отката.
Далее представлен код, показывающий, как
DiffGram создается и как
DataSet можно создать из
DiffGram:pwd (он находится в папке
ADOSample6). Начальная часть этого кода должна быть уже знакома. Мы определяем и задаем новый объект
DataSet,
ds, новый объект
SqlConnection,
conn и новый объект
SqlDataAdapter,
da. Мы соединяемся с базой данных, выбираем все строки из таблицы
Products, создаем новый объект
DataTable с именем
products и загружаем данные из базы данных в
DataSet:
private void button1_Click(object sender, System.EventArgs e) {
// новый объект DataSet
DataSet ds=new DataSet("XMLProducts");
// Сделать соединение и загрузить строки продуктов
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter da=new SqlDataAdapter("select * from products", conn);
// заполнить DataSet
da.Fill(ds, "products");
// редактируем первую строку
ds.Tables["products"].Rows[0]["ProductName"] = "NewProdName";
В следующем разделе мы сделаем следующие преобразования. Во-первых, изменим столбец
ProductName в первой строке на
NewProdName. Во-вторых, создадим новую строку в
DataTable, задавая значения столбцов и добавляя в конце новую строку данных в
DataTable.
// добавить новую строку
DataRow dr=ds.Tables["products"].NewRow();
dr["ProductId"]=100;
dr["CategoryId"]=2;
dr["Discontinued"]=false;
dr["ProductName"]="This is the new product";
dr["QuantityPerUnit"]=12;
dr["ReorderLevel"]=1;
dr["SupplierId"]=12;
dr["UnitPrice"]=23;
dr["UnitsInStock"]=5;
dr["UnitsOnOrder"]=0;
Tables["products"].Rows.Add(dr);
Это интересная часть кода. Прежде всего записывается схема с помощью
WriteXmlSchema. Это важно, так как нельзя будет заново считать в
DiffGram без схемы.
WriteXml с переданным в него параметром
XmlWriteMode.DiffGram создает в действительности
DiffGram. Следующая строка принимает сделанные изменения. Важно то, что
DiffGram создается до вызова
AcceptChanges, иначе не будет никакого различия между состоянием до того и после.
// записать схему
ds.WriteXmlSchema("..\\..\\..\\diffgram.xsd");
// создать DiffGram
ds.WriteXml("..\\..\\..\\diffgram.xml", XmlWriteMode.DiffGram);
ds.AcceptChanges();
// загрузить данные в сетку
dataGrid1.DataSource=ds;
dataGrid1.DataMember="products";
// новый объект XmlDataDocument
doc=new XmlDataDocument(ds);
// загрузить имена продуктов в список
XmlNodeList nodeLst=doc.SelectNodes("//ProductName");
foreach (XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml);
Чтобы вернуть данные в множество DataSet, можно сделать следующее:
DataSet dsNew = new DataSet();
dsNew.ReadXmlSchema("..\\..\\..\\diffgram.xsd");
dsNew.XmlRead("..\\..\\..\\diffgram.xml", XmlReadMode.DiffGram);
В этом примере создается новый объект множества данных
DataSet,
dsNew. Вызов метода
ReadXmlSchema создает новый объект
DataTable на основе информации схемы. В данном случае он будет клоном
DataTable продуктов. Теперь можно считать в
DiffGram.
DiffGram не содержит информации о схеме, поэтому важно, чтобы объект
DataTable был создан и готов к использованию до вызова метода
ReadXml. Вот образец того, как выглядит
DiffGram (
diffgram.xml):
<?xml version="1.0" standalone="yes"?>
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1">
<XMLProducts>
<products diffgr:id="products1" msdata:rowOrder="0" diffgr:hasChanged="modified">
<ProductID>1</ProduсtID>
<ProductName>NewProdName</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>1</CategoryID>
<QuantityPerUnit>10 boxes x 20 bags</QuantityPerUnit>
<UnitPrice>18</UnitPrice>
<UnitsInStock>39</UnitsInStock>
<UnitsOnOrder>0</UnitsOnOrder>
<ReorderLevel>10</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
<products diffgr:id="products2" msdata:rowOrder="1">
<ProductID>2</ProductID>
<ProduсtName>Chang</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>1</CategoryID>
<QuantityPerUnit>24 - 12 oz bottles</QuantityPerUnit>
<UnitPrice>19</UnitPrice>
<UnitsInStock>17</UnitsInStock>
<UnitsOnOrder>40</UnitsOnOrder>
<ReorderLevel>25</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
…
<products diffgr:id="products78" msdata:rowOrder="77" diffgr:hasChanges="inserted">
<ProductID>100</ProductID>
<ProductName>This is a new product</ProductName>
<SupplierID>12</SupplierID>
<CategoryID>2</CategoryID>
<QuantityPerUnit>12</QuantityPerUnit>
<UnitPrice>23</UnitPrice>
<UnitsInStock>5</UnitsInStock>
<UnitsOnOrder>0</UnitsOnOrder>
<ReorderLevel>1</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
</XMLProducts>
<diffgr:before>
<products diffgr:id="products1" msdata:rowOrder="0">
<ProductID>1</ProductID>
<ProductName>Chai </ProductName>
<SupplierID>1</SupplierID>
<CategoryID>1</CategoryID>
<QuantityPerUnit>10 boxes x 20 bugs </QuantityPerUnit>
<UnitPrice>18</UnitPrice>
<UnitsInStock>39</UnitsInStock>
<UnitsOnOrder>0</UnitsOnOrder>
<ReorderLevel>10</ReorderLevel>
<Discontinued>false</Discontinued>
</products>
</diffgr:before>
</diffgr:diffgram>
Заметим, каким образом повторяется каждая строка
DataTable, и что существует атрибут
diffgr:id для каждого элемента
<products>.
diffgr является префиксом пространства имен для
urn:schemas-microsoft-com:xml-diffgram-v1. Для модифицированной строки и для вставленной строки ADO.NET добавляет атрибут
diffgr:hasChanges. Здесь есть также элемент
<diffgr:before> после элемента
<XMLProducts>, который содержит элемент
<products>, указывающий на предыдущее содержание всех модифицированных строк. Для добавленной строки не существует
"before", поэтому здесь отсутствует элемент
<diffgr:before>, однако он присутствует для модифицированной строки.
После того как
DiffGram считан в
DataTable, он оказывается в состоянии, в котором он был бы после выполнения изменений в данных перед вызовом
AcceptChanges. В этом месте можно на самом деле откатить изменения, вызывая метод
RejectChanges. Проверяя свойство
DataRow.Item и передавая либо
DataRowVersion.Original, либо
DataRowVersion.Current, можно увидеть значения в
DataTable перед и после изменений.
Сериализация объектов в XML
Сериализация является процессом сохранения объекта на диске. Другая часть приложения или даже другое приложение могут десериализовать объект и он будет в том же состоянии, в каком он был до сериализации. Платформа .NET содержит два способа выполнения сериализации. Рассмотрим пространство имен
System.Xml.Serialization.
Как показывает имя, сериализация производится в формате XML. Это делается преобразованием открытых свойств объекта и открытых полей в элементы и/или атрибуты. Сериализатор XML не может преобразовать скрытые данные, а только открытые. Представляйте это как способ сохранения состояния объекта. Если необходимо сохранить скрытые данные, то используйте
BinaryFormatter в пространстве имен
System.Runtime.Serialization.Formatters.Binary. Можно также:
□ Определить, должны ли данные быть атрибутом или элементом.
□ Определить пространство имен.
□ Изменить имя атрибута или элемента.
Вместе с возможностью сериализовать только открытые данные, невозможно сериализовать графы объектов (объекты, которые достижимы из сериализуемого объекта). Это не является серьезным ограничением. При тщательном проектировании классов этого легко можно избежать. Если необходимо иметь возможность сериализовать открытые и скрытые данные, а также граф объектов, содержащий множество вложенных объектов, то можно будет воспользоваться пространством имен
System.Runtime.Serialization.Formatters.Binary.
Данные для сериализации могут быть примитивными типами данных, полями, массивами и XML, встроенным в форму объектов
XmlElement и
XmlAttribute. Связью между объектом и документом XML являются специальные атрибуты, которые аннотируют классы. Эти атрибуты используются для того, чтобы информировать сериализатор, как записать данные.
На платформе .NET существует инструмент, помогающий создавать атрибуты,— это утилита
xsd.exe, которая может делать следующее:
□ Генерировать схему XML из файла схемы XDR
□ Генерировать схему XML из файла XML
□ Генерировать классы
DataSet из файла схемы XSD
□ Генерировать классы времени выполнения, которые имеют специальные атрибуты для
XmlSerilization
□ Генерировать XSD из классов, которые уже были разработаны
□ Ограничивать список элементов, которые создаются в коде
□ Определять, на каком языке программирования должен быть представлен генерируемый код (C#, VB.NET, или JScript.NET)
□ Создавать схемы из типов в компилированных сборках
В документации платформы можно найти подробное описание параметров командной строки.
Несмотря на предлагаемые возможности, вовсе не обязательно использовать
xsd.exe, чтобы создать классы для сериализации. Рассмотрим простое приложение, которое сериализует класс, считывающий данные о продуктах, сохраненных ранее в этой главе (пример находится в папке
SerialSample1). В начале идет очень простой код, который создает новый объект
Product,
pd, и записывает некоторые данные:
private void button1_Click(object sender, System.EventArgs e) {
// новый объект Products
Products pd=new Products();
// задать некоторые свойства
pd.ProductXD=200;
pd.CategoryID=100;
pd.Discontinued=false;
pd.ProductName="Serialize Objects";
pd.QuantityPerUnit="6";
pd.ReorderLevel=1;
pd.SupplierID=1;
pd.UnitPrice=1000;
pd.UnitsInStock=10;
pd.UnitsOnOrder=0;
Метод
Serialize класса
XmlSerializer имеет шесть перегружаемых версий. Одним из требуемых параметров является поток для записи в него данных. Это может быть
Stream,
TextWriter или
XmlWriter. В данном случае мы создали объект
tr на основе
TextWriter. Затем необходимо создать объект
sr на основе
XmlSerializer.
XmlSerializer должен знать информацию о типе сериализуемого объекта, поэтому используется ключевое слово
typeof с указанием типа, который должен быть сериализован. После создания объекта
sr вызывается метод
Serialize, в который передается
tr (объект на основе
Stream) и объект, который необходимо сериализовать, в данном случае
pd. Не забудьте закрыть поток, когда закончите с ним работу.
//новый TextWriter и XmlSerializer
TextWriter tr=new StreamWriter("..\\..\\..\\serialprod.xml");
XmlSerializer sr=new XmlSerializer(typeof(Products));
// сериализуем объект
sr.Serialize(tr,pd);
tr.Close();
}
Здесь мы добавляем событие другой кнопки для создания нового объекта
newPd на основе
Products. В этот раз мы будем использовать объект
FileStream для чтения XML:
private void button2_Click(object sender, System.EventArgs e) {
// создаем ссылку на тип Products Products newPd;
// новый файловый поток для открытия сериализованного объекта
FileStream f=new FileStream("..\\..\\..\\serialprod.xml", FileMode.Open);
Здесь создается новый объект
XmlSerializer, таким образом передается информация о типе
Product. Затем можно вызвать метод
Deserialize. Отметим, что нам по-прежнему необходимо делать явное преобразование типа, когда создается объект
newPd. В этом месте newPd имеет такое же состояние, как и
pd:
// новый Serializer
XmlSerializer newSr=new XmlSerializer(typeof(Products));
// десериализация объекта
newPd=(Products)newSr.Deserialize(f);
// загружаем его в окно списка.
listBox1.Items.Add(newPd.ProductName);
f.Closed();
}
Теперь мы проверим класс
Products. Единственное различие между ним и любым другим классом, который можно записать, состоит в добавленных атрибутах. Не путайте эти атрибуты с атрибутами в документе XML. Эти атрибуты расширяют класс
SystemAttribute. Атрибут является некоторой декларативной информацией, которая может извлекаться во время выполнения с помощью CLR (см. в главе 6 более подробно). В данном случае добавляются атрибуты, которые описывают, как объект должен быть сериализован:
//класс, который будет сериализован,
//атрибуты определяют, как объект сериализуется.
[System.Xml.Serialization.XmlRootAttribute(Namespace="", IsNullable=false)]
public class Products {
[System.Xml.Serialization.XmlElementAttribute(IsNullable=false)]
public int ProductID;
[System.Xml.Serialization.XmlElementAttribute(IsNullable=false)]
public string ProductName;
[System.Xml.Serialization.XmlElementAttribute()]
public int SupplierID;
[System.Xml.Serialization.XmlElementAttribute()]
public int CategoryID;
[System.Xml.Serialization.XmlElementAttribute()]
public string QuantityPerUnit;
[System.Xml.Serialization.XmlElementAttribute()]
public System.Decimal UnitPrice;
[System.Xml.Serialization.XmlElementAttribute()]
public short UnitsInStock;
[System.Xml.Serialization.XmlElementAttribute()]
public short UnitsOnOrder;
[System.Xml.Serialization.XmlElementAttribute()]
public short ReorderLevel;
[System.Xml.Serialization.XmlElementAttribute()]
public bool Discontinued;
}
Созданный документ XML выглядит, как любой другой документ XML, который мы могли бы создать.
<?xml version="1.0" ?>
<Products xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<ProductID>200</ProductID>
<ProductName>Serialize Objects</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>100</CategoryID>
<QuantityPerUnit>6</QuantityPerUnit>
<UnitPrice>1000</UnitPrice>
<UnitsInStock>10</UnitsInStock>
<UnitsOnOrder>0</UnitsOnOrder>
<ReorderLevel>1</ReorderLevel>
<Discontinued>false</Discontinued>
</Products>
Здесь нет ничего необычного. Мы могли бы выполнить преобразование документа XML и вывести его как HTML, загрузить его в
DataSet с помощью ADO.NET, загрузить с его помощью
XmlDocument, как в примере, десериализовать его и создать объект в том же состоянии, которое имел
pd перед своей сериализацией (что соответствует событию второй кнопки).
Рассмотренный только что пример является очень простым. Обычно имеется ряд методов получения (get) и задания (set) свойств для работы с данными в объекте. Но что, если объект состоит из двух других объектов, или выводится из базового класса, из которого следуют и другие классы?
Такие ситуации обрабатываются с помощью класса
XmlSerializer. Давайте усложним пример (находится в
SerialSample2). Для большей реалистичности сделаем каждое свойство доступным через методы get и set:
private void button1_Click(object sender, System.EventArgs e) {
// новый объект products
Products pd=new Products();
// задать некоторые свойства
pd.ProductID=200;
pd.CategoryID=100;
pd.Discontinued=false;
pd.ProductName="Serialize Objects";
pd.QuantityPerUnit="6";
pd.ReorderLevel=1;
pd.SupplierID=1;
pd.UnitPrice=1000;
pd.UnitsInStock=10;
pd.UnitsOnOrder= 0;
pd.Discount=2;
//новые TextWriter и XmlSerializer
TextWriter tr=new StreamWriter("..\\..\\..\\serialprod1.xml");
XmlSerializer sr=new XmlSerializer(typeof(Products));
// сериализируем объект
sr.Serialize(tr, pd);
tr.Close();
}
private void button2_Click(object sender, System.EventArgs e) {
//создать ссылку на тип Products
Products newPd;
// новый файловый поток для открытия сериализуемого объекта
FileStream f=new FileStream("..\\..\\..\\serialprod1.xml", FileMode.Open);
// новый сериализатор
XmlSerializer newSr=new XmlSerializer(typeof(Products));
//десериализуем объект
newPd=(Products)newSr.Deserialize(f);
//загрузить его в окно списка.
listBox1.Items.Add(newPd.ProductName);
f.Close();
}
//класс, который будет сериализован.
//атрибуты определяют, как объект сериализуется
[System.Xml.Serialization.XmlRootAttribute()]
public class Products {
private int prodId;
private string prodName;
private int suppId;
private int catId;
private string qtyPerUnit;
private Decimal unitPrice;
private short unitsInStock;
private short unitsOnOrder;
private short reorderLvl;
private bool discont;
private int disc;
// добавлен атрибут Discount
[XmlAttributeAttribute(AttributeName="Discount")]
public int Discount {
get {return disc;}
set {disc=value;}
}
[XmlElementAttribute()]
public int ProductID {
get {return prodId;}
set {prodId=value;}
}
[XmlElementAttribute()]
public string ProductName {
get {return prodName;}
set {prodName=value;}
}
[XmlElementAttribute()]
public int SupplierID {
get {return suppId;}
set {suppId=value;}
}
[XmlElementAttribute()]
public int CategoryID {
get {return catId;}
set {catId=value;}
}
[XmlElementAttribute()]
public string QuantityPerUnit {
get {return qtyPerUnit;}
set {qtyPerUnit=value;}
}
[XmlElementAttribute()]
public Decimal UnitPrice {
get {return UnitPrice;}
set {unitPrice=value;}
}
[XmlElementAttribute()]
public short UnitsInStock {
get {return unitsInStock;}
set {unitsInStock=value;}
}
[XmlElementAttribute()]
public short UnitsOnOrder {
get {return unitsOrOrder;}
set {unitsOnOrder=value;}
}
[XmlElementAttribute()]
public short ReorderLevel {
get {return reorderLvl;}
set {reorderLvl=value;}
}
[XmlElementAttribute()]
public pool Discontinued {
get {return discont;}
set {discont=value;}
}
}
Выполнение этого кода вместо класса
Products в предыдущем примере даст те же самые результаты с одним исключением. Мы добавили атрибут
Discount, тем самым показав, что атрибуты также могут быть сериализуемыми. Вывод выглядит следующим образом (
serialprod1.xml):
<?xml version="1.0" encoding="utf-8"?>
<Products xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Discount="2">
<ProductID>200</ProductID>
<ProductName>Serialize Objects</ProductName>
<SupplierID>1</SupplierID>
<CategoryID>100</CategoryID>
<QuantityPerUnit>6</QuantityPerUnit>
<UnitPrice>1000</UnitPrice>
<UnitsInStock>10</UnitsInStock>
<UnitsOnOrder>0</UnitsOnOrder>
<ReorderLevel>1</ReorderLevel>
<Discontinued>false</Discontinued>
</Products>
Отметим атрибут
Discount элемента
Products. Поэтому теперь, когда определены средства задания и получения свойств, можно добавить более сложную проверку кода в свойствах.
Что можно сказать о ситуации, когда имеются производные классы и, возможно, свойства, которые возвращают массив?
XmlSerializer также это охватывает. Давайте обсудим более сложную ситуацию.
В событии
button1_Click создается новый объект на основе
Product и новый объект на основе
BookProduct (
newProd и
newBook). Мы добавляем данные в различные свойства каждого объекта и помещаем объекты в массив на основе
Product. Затем создается новый объект на основе
Inventory, которому в качестве параметра передается массив. Затем можно сериализовать объект
Inventory, чтобы впоследствии его восстановить:
private void button1_Click(object sender, System.EventArgs e) {
// создать новые объекты книги и книжной продукции
Product newProd=new Product();
BookProduct newBook=new BookProduct();
// задать некоторые свойства
newProd.ProductID=100;
newProd.ProductName="Product Thing";
newProd.SupplierID=10;
newBook.ProductID=101;
newBook.ProductName="How to Use Your New Product Thing";
newBook.SupplierID=10;
newBook.ISBN="123456789";
//поместить элементы в массив
Product[] addProd={newProd, newBook};
// новый объект Inventory с помощью массива addProd
Inventory inv=new Inventory();
inv.InventoryItems=addProd;
// сериализуем объект Inventory
TextWriter tr=new StreamWriter("..\\..\\..\\order.xml");
XmlSerializer sr=new XmlSerializer(typeof(Inventory));
sr.Serialize(tr, inv);
tr.Close();
}
Отметим в событии
button2_Click, что мы просматриваем массив во вновь созданном объекте
newInv, чтобы показать, что это те же данные:
private void button2_Click(object sender, System.EventArgs e) {
Inventory newInv;
FileStream f=new FileStream("..\\..\\..\\order.xml", FileMode.Open);
XmlSerializer newSr=new XmlSerializer(typeof{Inventory));
newInv=(Inventory)newSr.Deserialize(f);
foreach(Product prod in newInv.Inventory Items) listBox1.Items.Add(prod.ProductName);
f.Close();
}
public class inventory {
private Product[] stuff;
public Inventory() {}
Мы имеем
XmlArrayItem для каждого типа, который может быть добавлен в массив. Первый параметр определяет имя элемента в создаваемом документе XML. Если опустить этот параметр
ElementName, то элементы получат имя типа объекта (в данном случае
Product и
BookProduct). Существует также класс
XmlArrayAttribute, который будет использоваться, если свойство возвращает массив объектов или примитивных типов. Так как мы возвращаем в массиве различные типы, то используется объект
XmlArrayItemAttribute, который предоставляет более высокий уровень управления:
// необходимо иметь запись атрибута для каждого типа данных
[XmlArrayItem("Prod", typeof(Product)), XmlArrayItem("Book", typeof(BookProduct))]
//public Inventory(Product [] InventoryItems) {
// stuff=InventoryItems;
//}
public Product[] InventoryItems {
get {return stuff;}
set {stuff=value;}
}
}
//класс Product
public class Product {
private int prodId;
private string prodName;
private int suppId;
public Product() {}
public int ProductID {
get {return prodId;}
set {prodId=value;}
}
public string ProductName {
get {return prodName;}
set {prodName=value;}
}
public int SupplierID {
get {return suppId;}
set {suppId=value;}
}
}
// Класс Bookproduct
public class BookProduct: Product {
private string isbnNum;
public BookProduct() {}
public string ISBN {
get {return isbnNum;}
set {isbnNum=value;}
}
}
В этот пример добавлено два новых класса. Класс
Inventory будет отслеживать то, что добавляется на склад. Можно добавлять продукцию на основе класса
Product или класса
BookProduct, который расширяет
Product. В классе
Inventory содержится массив добавленных объектов и в нем могут находиться как
BookProducts, так и
Products. Вот как выглядит документ XML:
<?xml version="1.0" ?>
<Inventory xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<InventoryItems>
<Prod>
<ProductID>100</ProductID>
<ProductName>Product Thing</ProductName>
<SupplierID>10</SupplierID>
</Prod>
<Book>
<ProductID>101</ProductID>
<ProductName>How to Use Your New Product Thing</ProductName>
<SupplierID>10</SupplierID>
<ISBN>123456789</ISBN>
</Book>
</InventoryItems>
</Inventory>
Все это работает прекрасно, но как быть в ситуации, когда нет доступа к исходному коду типов, которые будут сериализироваться? Невозможно добавить атрибут, если отсутствует исходный код. Существует другой способ. Можно воспользоваться классами
XmlAttributes и
XmlAtrtributeOverrides. Вместе эти классы позволят выполнить в точности то, что только что было сделано, но без добавления атрибутов. Вот пример, находящийся в папке
SerialSample4:
private void button1_Click(object sender, System.EventArgs e) {
// создать объект XmlAttributes XmlAttributes attrs=new XmlAttributes();
// добавить типы объектов, которые будут сериализированы
attrs.XmlElements.Add(new XmlElementAttribute("Book", typeof(BookProduct)));
attrs.XmlElements.Add(new XmlElementAttribute("Product", typeof(Product)));
XmlAttributeOverrides attrOver=new XmlAttributeOverrides();
//добавить к коллекций атрибутов
attrOver.Add(typeof(Inventory), "InventoryItems", attrs);
// создать объекты Product и Book
Product newProd=new Product();
BookProduct newBook=new BookProduct();
newProd.ProductID=100;
newProd.ProductName="Product Thing";
newProd.SupplierID=10;
newBook.ProductID=101;
newBook.ProductName="How to Use Your New Product Thing";
newBook.SupplierID=10;
newBook.ISBN="123456789";
Product[] addProd={newProd, newBook};
//Product[] addProd={newBook};
Inventory inv=new Inventory();
inv.InventoryItems=addProd;
TextWriter tr=new StreamWriter("..\\..\\..\\inventory.xml");
XmlSerializer sr=new XmlSerializer(typeof(Inventory), attrOver);
sr.Serialize(tr, inv);
tr.Close();
}
private void button2_Click(object sender, System.EventArgs e) {
//необходимо выполнить тот же процесс для десериализации
// создаем новую коллекцию XmlAttributes
XmlAttributes attrs=new XmlAttributes();
// добавляем информацию о типе к коллекции элементов
attrs.XmlElements.Add(new XmlElementAttribute("Book", typeof(BookProduct)));
attrs.XmlElements.Add(new XmlElementAttribute("Product", typeof(Product)));
XmlAttributeOverrides attrOver=new XmlAttributeOverrides();
//добавляем к коллекции Attributes (атрибутов)
attrOver.Add(typeof(Inventory), "InventoryItems", attrs);
//нужен новый объект Inventory для десериализаций в него
Inventory newInv;
// десериализуем и загружаем данные в окно списка из
// десериализованного объекта
FileStream f=new FileStream("..\\..\\..\\inventory.xml", FileMode.Open);
XmlSerializer newSr=new XmlSerializer(typeof(Inventory).attrOver);
newInv=(Inventory)newSr.Deserialize(f);
if (newInv!=null) {
foreach(Product prod in newInv.InventoryItems) listBox1.Items.Add(prod.ProductName);
}
f.Close();
}
// это те же классы, что и в предыдущем примере
// за исключением удаленных атрибутов
// из свойства InventoryItems для Inventory
public class Inventory {
private Product[] stuff;
public Inventory() {}
public Product[] InventoryItems {
get {return stuff;}
set {stuff=value;}
}
}
public class Product {
private int prodId;
private string prodName;
private int suppId;
public Product() {}
public int ProductID {
get {return prodId;}
set {prodId=value;}
}
public string ProductName {
get {return prodName;}
set {prodName=value;}
}
public int SupplierID {
get {return suppId;}
set {suppId=value;}
}
}
public class BookProduct:Product {
private string isbnNum;
public BookProduct() {}
public string ISBN {
get {return isbnNum;}
set {isbnNum=value;}
}
}
Это тот же пример, что и раньше, но первое, что необходимо заметить,— здесь нет добавленных в класс
Inventory атрибутов. Поэтому в данном случае представьте, что классы
Inventory,
Product и производный класс
BookProduct находятся в отдельной DLL, и у нас нет исходного кода.
Первым шагом в процессе является создание объекта на основе
XmlAttributes, и объекта
XmlElementAttribute для каждого типа данных, который будет переопределяться:
XmlAttributes attrs=new XmlAttributes();
attrs.XmlElements.Add(new XmlElementAttribute("Book", typeof(BookProduct)));
attrs.XmlElements.Add(new XmlElementAttribute("Product", typeof(Product)));
Здесь мы добавляем новый
XmlElementAttribute к коллекции
XmlElements класса
XmlAttributes. Класс
XmlAttributes имеет свойства, соответствующие атрибутам, которые могут применяться;
XmlArray и
XmlArrayItems, которые мы видели в предыдущем примере, являются только парой. Теперь мы имеем объект
XmlAttributes с двумя объектами на основе
XmlElementAttribute, добавленными к коллекции
XmlElements. Далее создадим объект
XmlAttributeOverrides:
XmlAttributeOverrides attrOver = new XmlAttributeOverride();
attrOver.Add(typeof(Inventory) , "Inventory Items", attrs);
Meтод
Add имеет две перегружаемые версии. Первая получает информацию о типе переопределяемого объекта и объект
XmlAttributes, который был создан ранее. Вторая версия та, что мы используем, получает также с строковое значение, которое является членом в переопределенном объекте. В нашем случае мы хотим переопределить член
InventoryItems в классе
Inventory.
Теперь создадим объект
XmlSerializer, добавляя объект
XmlAttributeOverridesв качестве параметра.
XmlSerializer уже знает, какие типы мы хотим переопределить и что нам нужно вернуть для этих типов. Если выполнить метод
Serialize, то получится следующий вывод XML:
<?xml version="1.0"?>
<Inventory xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Products>
<ProductID>100</ProductID>
<ProductName>Product Thing</ProductName>
<SupplierID>10</SupplierID>
</Product>
<Book>
<ProductID>101</ProductID>
<ProductName>How to Use Your New Product Thing</ProductName>
<SupplierID>10</SupplierID>
<ISBN>123456789</ISBN>
</Book>
</Inventory>
Мы получили тот же самый XML, что и в предыдущем примере. Чтобы десериализовать этот объект и воссоздать объект на основе Inventory, с которого мы начали, необходимо создать все те же объекты
XmlAttributes,
XmlElementAttribute и
XmlAttributeOverrides, которые создаются при сериализации объекта. Когда это будет сделано, можно прочитать XML и воссоздать объект
Inventory, как это делалось раньше. Вот код для десериализации объекта
Inventory:
private void button2_Click(object sender, System.EventArgs e) {
XmlAttributes attrs=new XmlAttributes();
attrs.XmlElements.Add(new XmlElementAttribute("Book", typeof(BookProduct)));
attrs.XmlElements.Add(new XmlElementAttribute("Product", typeof(Product)));
XmlAttributeOverrides attrOver=new XmlAttributeOverrides();
attrOver.Add(typeof(Inventory), "InventoryItems", attrs);
Inventory newInv;
FileStream f=new FileStream("..\\..\\..\\inventory.xml", FileMode.Open);
XmlSerializer newSr=new XmlSerializer(typeof(Inventory), attrOver);
newInv=(Inventory)newSr.Deserialize(f);
foreach(Product prod, in newInv.InventoryItems) listBox1.items.Add(prod.ProductName);
f.Close();
}
Отметим, что первые несколько строк кода идентичны коду, который использовался для сериализации объекта.
Пространство имен
XmlSerialize предоставляет мощный набор инструментов. Сериализуя объекты в XML, а не в двоичный формат, мы получаем дополнительные возможности, что может действительно увеличить гибкость проектирования.
Заключение
В этой главе рассматривались широкие возможности пространства имен
System.Xml платформы .NET. Было показано, как прочитать и записать документы XML с помощью классов на основе
XMLReader и
XMLWriter, как в .NET реализована DOM и как использовать возможности DOM. Мы увидели, что XML и ADO.NET действительно очень тесно связаны.
DataSet и документ XML являются двумя различными представлениями одной и той же базовой архитектуры. Мы сериализовали объекты в XML и смогли вернуть их обратно с помощью вызова пары методов. Комбинация
Reflection и
XMLSerilization приводит к некоторым уникальным конструкциям. И, конечно, были рассмотрены
XPath и
XslTransform. В течение ближайших нескольких лет XML станет, если уже не стал, важной частью разработки приложений. Платформа .NET сделала доступным мощный набор инструментов для работы с XML.
Глава 14
Операции с файлами и реестром
В этой главе будет рассмотрено выполнение в C# задач, включающих чтение и запись в файлы и в системный реестр. В частности, будут охвачены следующие вопросы:
□ Исследование структуры каталога, выяснение, какие файлы и папки присутствуют и проверка их свойств
□ Перемещение, копирование и удаление файлов и папок
□ Чтение и запись текста в и из файлов
□ Чтение и запись в реестр
Компания Microsoft предоставила очень интуитивную объектную модель, охватывающую эти области, и в ходе этой главы мы покажем, как использовать классы на основе .NET для выполнения упомянутых выше задач. Для случая операций с файловой системой соответствующие классы почти все находятся в пространстве имен System.IO, в то время как операции с реестром связаны с парой классов в пространстве имен System.Win32.
Классы на основе .NET включают также ряд классов и интерфейсов в пространстве имен System.Runtime.Serilization, которые связаны с сериализацией, то есть процессом преобразования некоторых данных (например, содержимого документа) в поток байтов для хранения в каком либо месте. Мы не будем рассматривать эти классы в данной главе, так как сосредоточимся на классах, которые предназначены для прямого доступа к файлам.
Отметим, что хотя безопасность влияет на все области, но особенно она важна при модификации файлов или записей реестра. Система безопасности рассматривается отдельно в главе 25. В этой главе мы будем предполагать, что имеются достаточные права доступа для выполнения всех примеров, которые модифицируют файлы или записи реестра, что обеспечивается, например, при использовании учетной записи с полномочиями администратора.
Управление файловой системой
Классы, которые используются для просмотра файловой системы и выполнения таких операций, как перемещение, копирование и удаление файлов, показаны на следующей диаграмме. Пространство имен каждого класса показано в скобках под именем каждого класса на диаграмме:
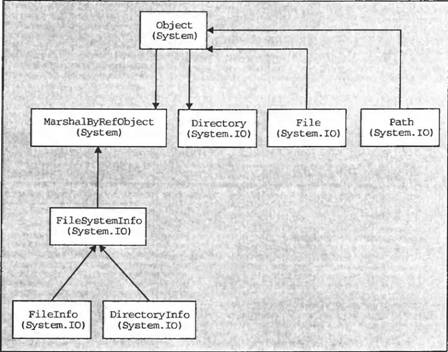
Назначение этих классов следующее:
□
System.MarshalByRefObject — класс базового объекта для классов .NET, которые являются удаленными. Допускает маршализацию данных между прикладными доменами.
□
FileSystemInfo — базовый класс, который представляет любой объект файловой системы.
□
FileInfo и
File — представляют файл в файловой системе.
□
DirectoryInfo и
Directory — представляют папку в файловой системе.
□
Path — содержит статические члены, которые можно использовать для манипуляций именами путей доступа.
Отметим, что в Windows объекты, которые содержат файлы и используются для организации файловой системы, называются папками. Например, в пути доступа C:\My Documents\ReadMe.txt файлом является ReadMe.txt, а My Documents — папкой. Папка (folder) является специфическим для Windows терминам: практически во всех других операционных системах вместо папки используется термин каталог (directory). В соответствии с желанием Microsoft, чтобы .NET была максимально независимой от операционной системы, соответствующие базовые классы .NET называются Directory и DirectoryInfo. Однако в связи с возможной путаницей с каталогами LDAP (обсуждаемыми в главе 15), и в связи с тем, что эта книга посвящена Windows, здесь используется термин папка.
Классы .NET, представляющие файлы и папки
Из приведенного выше списка можно видеть, что существуют два класса, используемых для представления папки, и два класса для файла. Какой из этих классов будет наиболее подходящим, зависит в большой степени от того, сколько раз необходимо получать доступ к папке или файлу:
□
Directory и
File содержат только статические методы и никогда не создают экземпляров. Эти классы применяются с помощью предоставления пути доступа к соответствующему объекту файловой системы, когда вызывается метод-член. Если нужно выполнить только одну операцию на папке или файле, то эти классы более эффективны, так как не требуют создания экземпляра класса .NET.
□
DirectoryInfo и
FileInfo реализуют приблизительно те же открытые методы, что и
Directory и
File, а также некоторые открытые свойства и конструкторы, но они имеют состояние и члены этих классов не являются статическими. На самом деле необходимо создать экземпляры этих классов, и при этом каждый экземпляр ассоциируется с определенной папкой или файлом. Это означает, что эти классы являются более эффективными, если выполняется несколько операций с помощью одного и того же объекта, так как они будут считывать аутентификационные и другие данные при создании соответствующего объекта файловой системы, а затем им не понадобиться больше считывать эту информацию, независимо от того, сколько методов вы будете вызывать на каждом объекте (экземпляре класса). Для сравнения, соответствующим классам без состояния понадобиться снова проверять данные файла или папки для каждого вызываемого метода.
В этом разделе мы будем в основном использовать классы
FileInfo и
DirectoryInfo, но оказывается, что многие (но не все) вызываемые методы реализуются также классами
File и
Directory (хотя в этих случаях эти методы требуют дополнительный параметр, имя пути доступа объекта файловой системы и пара методов имеют немного отличные имена). Например:
FileInfo MyFile = new FileInfo(@"C:\Program Files\My Program\ReadMe.txt");
MyFile.CopyTo(@"D:\Copies\ReadMe.txt");
Имеет тот же результат, что и:
File.Copy(@"C:\Program Files\My Program\ReadMe.txt", @"D:\Copies\ReadMe.txt");
Первый фрагмент кода будет выполняться немного дольше, так как он требует создания экземпляра объекта
FileInfo —
MyFile, но он оставляет
MyFile готовым для выполнения дальнейших действий на том же файле.
Для создания экземпляра класса
FileInfo или
DirectoryInfo в конструктор передается строка, содержащая путь доступа к соответствующей файловой системе. Мы только что проиллюстрировали процесс для файла. Для папки код выглядит аналогично:
DirectoryInfo MyFolder = new DirectoryInfo(@"C:\Program Files");
Если путь доступа представляет объект, который не существует, то исключение будет порождено не во время создания, а в тот момент, когда будет вызван метод, которому потребовался объект соответствующей файловой системы. Можно определить существует ли объект и имеет ли соответствующий тип, проверяя свойство Exists, которое реализовано для обоих этих классов:
FileInfo Test = new FileInfo(@"C:\Windows");
Console.WriteLine(Test.Exists.ToString());
Console.WriteLine(Test.CreationTime.ToString());
Отметим, что для того, чтобы это свойство возвращало
true, соответствующий объект файловой системы должен быть соответствующего типа. Другими словами, если создается экземпляр объекта
FileInfo, содержащий путь доступа папки или, если создается объект
DirectoryInfo, задающий путь доступа файла,
Exists будет иметь значение
false. С другой стороны, большинство свойств и методов этих объектов будут возвращать значение, если вообще это возможно. Но они не обязательно порождают исключение из-за того, что был вызван неправильный тип объекта, а только в том случае, если требовалось выполнить что-то реально невозможное. Например, приведенный выше фрагмент кода сначала выведет
false (так как
C:\Windows является папкой), но затем все равно правильно покажет время создания папки, так как в папке имеется эта информация. С другой стороны, если затем попробовать открыть папку, как если бы это был файл, с помощью метода
FileInfo.Open(), то будет порождено исключение.
После того, как определено, что соответствующий объект файловой системы существует, можно (если используется класс
FileInfo или
DirectoryInfo) найти о нем информацию, используя ряд свойств, включающих:
| Имя |
Назначение |
CreationTime |
Время создания файла или папки. |
DirectoryName(FileInfo), Parent(DirectoryInfo) |
Полный путь доступа содержащей папки. |
Exists |
Существует ли файл или папка. |
Extension |
Расширение файла. Возвращается пустым для папок. |
FullName |
Полное имя пути доступа файла или папки. |
LastAccessTime |
Время последнего доступа к файлу или папке. |
LastWriteTime |
Время последней модификации файла или папки. |
Name |
Имя файла или папки. |
Root |
(Только DirectoryInfo.) Корневая часть пути доступа. |
Length |
(Только FileInfo.) Возвращает размер файла в байтах. |
Можно также выполнить действия на объекте файловой системы с помощью следующих методов:
| Имя |
Назначение |
Create() |
Создает папку или пустой файл с заданным именем. Для FileInfo он возвращает также объект потока, чтобы позволить записать в файл. Потоки будут рассмотрены позже. |
Delete() |
Удаляет файл или папку. Для папок существует вариант рекурсивного метода Delete. |
MoveTo() |
Перемещает и/или переименовывает файл или папку. |
CopyTo() |
(Только FileInfo.) Копирует файл. Отметим, что не существует метода копирования для папок. Если копируются все деревья каталогов, то необходимо индивидуально скопировать каждый файл и создать новые папки, соответствующие старым папкам. |
GetDirectories() |
(Только DirectoryInfo.) Возвращает массив объектов DirectoryInfo, представляющих все папки, содержащиеся в этой папке. |
GetFiles() |
(Только DirectoryInfo.) Возвращает массив объектов FileInfo, представляющих все папки, содержащиеся в этой папке. |
GetFileSystemObjects() |
(Только DirectoryInfo.) Возвращает объекты FileInfo и DirectoryInfo, представляющие все объекты, содержащиеся в этой папке, как массив ссылок FileSystemInfo. |
Отметим, что приведенные выше таблицы показывают основные свойства и методы, и не являются исчерпывающими.
В приведенных выше таблицах не перечислены большинство свойств или методов, которые позволяют записывать или читать данные в файлах. Это в действительности делается с помощью потоковых объектов, которые будут рассмотрены позже. FileInfo реализует также ряд методов (Open(), OpenRead(), OpenText(), OpenWrite(), Create(), CreateText(), которые возвращают объекты потоков для этой цели).
Интересно то, что время создания, время последнего доступа, и время последней записи являются изменяемыми:
// Test является FileInfo или DirectoryInfo. Задать время создания
// как 1 Jan 2001, 7.30 am
Test.CreationTime = new DateTime(2001, 1, 1, 7, 30, 0);
Это может показаться странным, но на самом деле достаточно полезно. Например, если имеется программа, которая эффективно модифицирует файл, просто считывая его, затем удаляя его и создавая новый файл с новым содержимым, то будет желательно изменить дату создания, чтобы противопоставить первоначальной дате создания старого файла.
Класс Path
Класс
Path не является классом, экземпляры которого будут создаваться. Скорее он предоставляет некоторые статические методы, которые облегчают работу с путями доступа. Например, предположим, что необходимо вывести имя полного пути доступа для файла
ReadMe.txt в папке
C:\My Documents. Путь доступа к файлу можно найти с помощью следующей операции:
Console.WriteLine(Path.Combine(@"C:\My Documents", "ReadMe.txt"));
Использовать класс Path значительно проще, чем пытаться справиться с символами-разделителями вручную, потому что класс
Path знает различные форматы имен путей доступа в различных операционных системах. Во время написания книги Windows являлась единственной операционной системой, поддерживаемой .NET, но если, например, .NET будет в дальнейшем перенесена на Unix, то
Path сможет справиться с путями доступа Unix, где в качестве разделителя в именах путей доступа используется /, а не \.
Path.Combine является методом этого класса, который будет вероятно использоваться чаще всего, но
Path реализует также другие методы, которые предоставляют информацию о пути доступа или требуемом для него формате.
В следующем разделе будет дан пример, который поясняет, как просмотреть каталоги и увидеть свойства файлов
Пример: файловый браузер
В этом разделе представлен пример приложения C#, называемого
FileProperties.
FileProperties представляет простой интерфейс пользователя, который позволяет перемещаться по файловой системе и видеть время создания время последнего доступа, время последней записи и размер файлов.
Приложение
FileProperties выглядит следующим образом. Пользователь вводит имя папки или файла в основное текстовое поле в верхней части окна и нажимает кнопку
Display. Если вводится путь доступа к папке, ее содержимое выводится в окне списка. Если ввести путь доступа к файлу, то данные о нем появятся в текстовых полях в нижней части формы, а содержимое папки — в окне списка. На экране показано приложение
FileProperties, используемое для просмотра папки:

Пользователь может очень легко перемещаться по файловой системе, щелкая мышью на любой из папок в правом окне списка для перехода в эту папку или на кнопке Up для перемещения в родительскую папку. На приведенном выше экране в основном текстовом поле введено C:\4990, чтобы получить содержимое этого раздела, который использует окно списка для дальнейшего перемещения. Пользователь может также выбрать файл, щелкая на его имени в окне списка, в этом случае его свойства выводятся в текстовых полях:

Обратите внимание, что при желании можно также вывести время создания, время последнего доступа и время последнего изменения для папок —
DirectoryInfo реализует соответствующие свойства. Мы выводим эти свойства только для выбранного файла, чтобы сохранить простоту приложения.
Мы создаем проект как стандартное приложение C# Windows в Visual Studio.NET и добавляем различные текстовые поля и окно списка из области Windows Forms в панели инструментов. Затем элементы управления переименовываются в более понятные имена
txtBoxInput,
txtBoxFolder,
buttonDisplay,
buttonUp,
listBoxFiles,
listBoxFolders,
textBoxFileName,
textBoxCreationTime,
txtBoxLastAccessTime,
txtBoxLasrWriteTime и
textBoxFileSize.
После чего добавляется следующий код:
using System;
using System.Drawing;
using System.Collections;
using System.ComponentModel;
using System.Windows.Forms;
using System.IO;
Нам необходимо делать это для всех примеров в этой главе, связанных с файловой системой, но мы не будем явно показывать этот код в остальных примерах. Затем к основной форме добавляется поле-член:
public class Form1 : System.Windows.Forms.Form {
#region Member Fields
private string currentFolderPath;
currentFolderPath будет содержать путь доступа папки, содержимое которой будет выводится в данный момент в окне списка.
Теперь нам нужно добавить обработку генерируемых пользователем событий. При этом возможны следующие способы вывода:
□ Пользователь щелкает на кнопке Display. В этом случае необходимо определить, что введенный пользователем текст в основном текстовом поле является путем доступа к файлу или папке. Если это папка, мы перечисляем файлы и вложенные папки этой папки в окне списка. Если это файл, мы делаем это для папки, содержащей этот файл, но также выводим свойства файла в нижних текстовых полях.
□ Пользователь щелкает на имени файла в окне списка Files. В этом случае мы выводим свойства этого файла в нижних текстовых полях.
□ Пользователь щелкает на имени папки в окне списка Folders. В этом случае мы очищаем все элементы управления и затем выводим содержимое этой вложенной папки в окне списка.
□ Пользователь щелкает на кнопке Up. В этом случае мы очищаем все элементы управления и затем выводим содержимое родительской папки в окне списка.
Прежде чем показать код обработчиков событий, приведем код методов. Для начала необходимо очистить содержимое всех элементов управления. Этот метод вполне очевиден:
protected void ClearAllFields() {
listBoxFolders.Items.Clear();
listBoxFiles.Items.Clear();
txtBoxFolder.Text = "";
txtBoxFileName.Text = "";
txtBoxCreationTime.Text = "";
txtBoxLastAccessTime.Text = "";
txtBoxLastWriteTime.Text = "";
txtBoxSize.Text ="";
}
Затем определяется метод
DisplayFileInfo(), который обрабатывает процесс вывода информации для заданного файла в текстовых полях. Этот метод получает один параметр, полное имя пути доступа файла и работает, создавая объект
FileInfo на основе этого пути доступа:
protected void DisplayFileInfo(string fileFullName) {
txtBoxFileName.Text = TheFile.Name;
txtBoxCreationTime.Text = TheFile.CreationTime.ToLongTimeString();
txtBoxLastAccessTime.Text = TheFile.LastAccessTime.ToLongDateString();
txtBoxLastWriteTime.Text = TheFile.LastWriteTime.ToLongDateString();
txtBoxFileSize.Text = TheFile.Length.ToString() + " bytes";
}
Отметим, что здесь мы воздержались от порождения исключения в случае каких-либо проблем с местоположением файла. Исключение будет обрабатываться в вызывающей процедуре (в одном из обработчиков событий). Наконец, мы определяем метод
DisplayFolderList(), который выводит содержимое данной папки в двух окнах списка. Полное имя пути доступа папки передается в этот метод в качестве параметра:
protected void DisplayFolderList(string folderFullName) {
DirectoryInfo TheFolder = new DirectoryInfo(folderFullName);
if (TheFolder.Exists)
throw new DirectoryNotFoundException("Folder not found: " + folderFullName);
ClearAllFields();
txtBoxFolder.Text = TheFolder.FullName;
currentFolderPath = TheFolder.FullName;
// перечисляем все папки, вложенные в папку
foreach(DirectoryInfo NextFolder in TheFolder.GetDirectories())
listBoxFolders.Items.Add(NextFolder.Name);
// перечисляем все файлы в папке
foreach (FileInfo NextFile in TheFolder.GetFiles())
listBoxFiles.Items.Add(NextFile.Name);
}
Теперь мы проверим программы обработки событий. Обработчик события нажатия на кнопку
Display является самым сложным, так как ему необходимо обработать три различные возможности для вводимого пользователем текста. Это может быть имя пути доступа папки, имя пути доступа файла или ни то, ни другое:
protected void onDisplayButtonClick(object sender, EventArgs e) {
try {
string FolderPath = txtBoxInput.Text;
DirectoryInfo TheFolder = new DirectoryInfo(FolderPath);
if (TheFolder.Exists) {
DisplayFolderList(TheFolder.FullName);
return;
}
FileInfo TheFile = new FileInfo(FolderPath);
if (TheFile.Exists) {
DisplayFolderList(TheFile.Directory.FullName);
int Index = listBoxFiles.Items.IndexOf(TheFile.Name);
listBoxFiles.SetSelected(Index, true);
return;
}
throws
new FileNotFoundException("There is no file or folder with " + "this name: " + txtBoxInput.Text);
} catch (Exception ex) {
MessageBox.Show(ex.Message);
}
}
В приведенном выше коде мы определяем, что поставляемый текст представляет папку или файл, создавая по очереди экземпляры
DirectoryInfo и
FileInfo и проверяя свойство
Exists каждого объекта. Если ни один из них не существует, то порождается исключение. Если это папка, вызывается метод
DisplayFolderList, чтобы заполнить окна списков. Если это файл, то необходимо заполнить окна списков и текстовые поля, которые выводят свойства файла. Мы обрабатываем этот случай, заполняя сначала окна списков. Затем программным путем выбирается соответствующее имя файла в окне списка файлов. Это имеет в точности тот же результат, как если бы пользователь выбрал этот элемент, порождается событие выбора элемента. Затем можно просто выйти из текущего обработчика событий, зная, что обработчик событий выбранного элемента будет немедленно вызван для вывода свойств файла.
Следующий код является обработчиком событий, который вызывается, когда в окне списка выбирается элемент либо пользователем, либо, как указано выше, программным путем. Он создает полное имя пути доступа выбранного файла и передает его в метод
DisplayFileInfo(), который был показан ранее:
protected void OnListBoxFilesSelected(object sender, EventArgs e) {
try {
string SelectedString = listBoxFiles.SelectedItem.ToString();
string FullFileName = Path.Combine(currentFolderPath, SelectedString);
DisplayFileInfo(FullFileName);
} catch (Exception ex) {
MessageBox(ex.Message);
}
}
Обработчик событий выбора папки в окне списка папок реализуется похожим образом, за исключением того, что в этом случае вызывается
DisplayFolderList() для обновления содержимого окон списков:
protected void OnListBoxFoldersSeleeted(object sender, EventArgs e) {
try {
string SelectedString = listBoxFolders.SelectedItem.ToString();
string FullPathName = Path.Combine(currentFolderPath, SelectedString);
Display FolderList(FullPathName);
} catch (Exception ex) {
MessageBox.Show(ex.Message);
}
}
Наконец, когда происходит щелчок на кнопке Up, должен также вызываться метод
DisplayFolderList(), за исключением того, что в этот раз необходимо получить путь доступа предка выводимой в данный момент папки. Это достигается с помощью свойства
FileInfo.DirectoryName, которое возвращает путь доступа родительской папки
protected void OnUpButtonClick(object sender, EventArgs e) {
try {
string FolderPath = new FileInfo(currentFolderPath).DirectoryName;
DisplayFolderList(FolderPath);
} catch (Exception ex) {
MessageBox(ex.Message);
}
}
Отметим, что для этого проекта мы не показали код, который добавляет методы обработки событий к соответствующим событиям элементов управления. Нам не нужно добавлять этот код вручную, так как согласно замечанию в главе 7 можно использовать окно Properties в Visual Studio для связывания каждого метода обработки событий с событием.
Перемещение, копирование и удаление файлов
Мы уже упоминали, что перемещение и удаление файлов или папок делается методами
MoveTo() и
Delete() классов
FileInfo и
DirectoryInfo. Эквивалентными методами в классах File и Directory являются Move() и Delete(). Классы FileInfo и File также соответственно реализуют методы
CopyTo() и
Copy(). Однако не существует методов для копирования полных папок, необходимо сделать это, копируя каждый файл в папке.
Использование всех этих методов является вполне понятным, все детали можно найти в MSDN. В этом разделе мы проиллюстрируем их использование для определенных случаев вызова статических методов
Move(),
Copy() и
Delete() на классе
File. Чтобы сделать это, мы преобразуем предыдущий пример
FileProperties в новый пример
FilePropertiesAndMovement. Этот пример будет иметь дополнительное свойство, позволяющее при выводе свойств файла выполнить удаление этого файла или перемещение или копирование его в другое место.
Пример FilePropertiesAndMovement
Пример выглядит следующим образом: ...
 Скачать или читать эту книгу на КулЛиб
Скачать или читать эту книгу на КулЛиб